Im overfitting a CNN on 3 data samples one of each class. During training i run for 15 epochs.
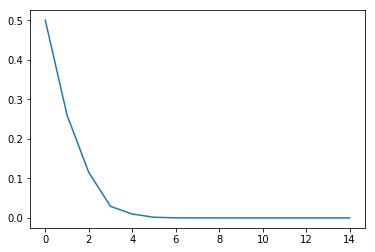
The loss is decreasing beautifully.
However when i want to find train accuracy, i run the same three images through, with model.eval() and the model just predict constant class and thus gets 33.3 percent accuracy.
If i use model.train() it gets 100 percent accuracy. This is what i expect as the loss is so low and the model have overfitted.
And remember its the same three samples i use when training which is should be able to fit perfectly.
Is there something i have misunderstod? I use batchnorm layers and dropout so i thought i had to use model.eval() in order to use the neurons that have been dropped etc.
Your BatchNorm layers might have a wrong estimate of the running mean and std if you just use 3 samples.
Try to remove them or use something like InstanceNorm for such a small sample.
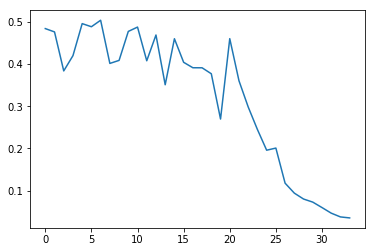
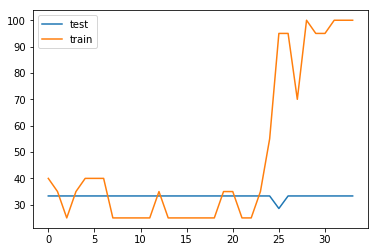
I tried for a slightly larger data set (50 samples), the loss still decreases and i still overfit (after around 25 epochs). But this is still only with model.train() and not with model.eval(). With model.eval() the accuracies never increases, even with dropping loss.
The loss:
The accuracies:
The testing stays same through entire training.
I will try using InstanceNorm() and see if that improves the issue.
I think, this is interesting. By whatever idealogy that we know about training, testing paradigm, I would hope that whatever the data we train on, the model already knows/can memorize them. Given that the model is trained to the level to overfit those data, I would not expect the model to perform pretty bad on the same data.