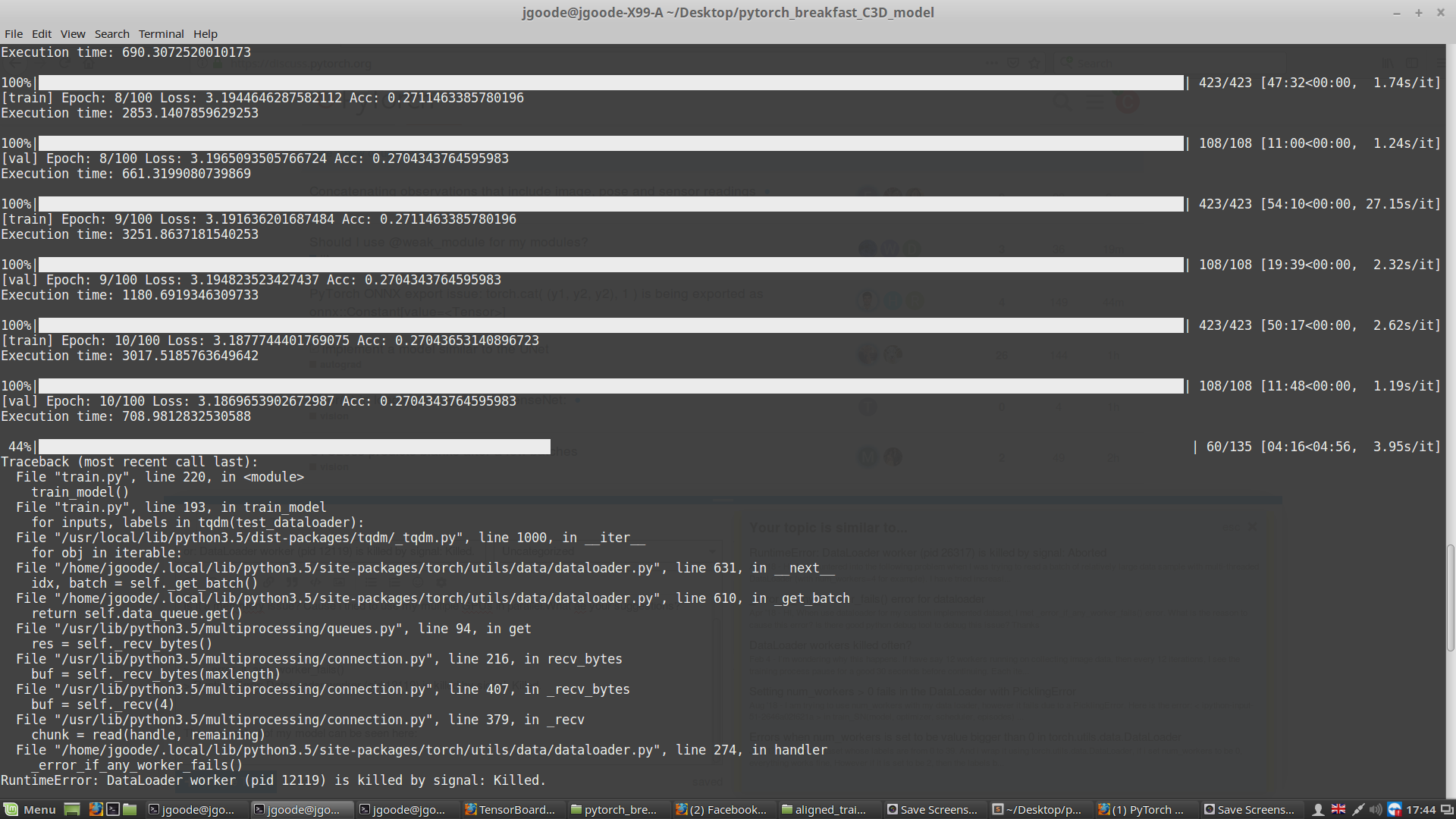
This is the error I get when i train my model. The error occured at the 10th epoch after running for 1 day. Is it a memmory issue? Cause i tried to use my multiple GPUs in parallel.What are your suggestions?
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 12119) is killed by signal: Killed.
The screenshot of my model can be seen here:
I am just getting my feet wet with PyTorch, and I am seeing the same behavior, with no GPU.
Running a CNN very similar to the 60 minute blitz tutorial, with two classes and approximately 12,000 training images, I get the following at epoch 87:
Traceback (most recent call last):
File “training.py”, line 69, in
loss.backward()
File “/home/goldin/miniconda3/lib/python3.7/site-packages/torch/tensor.py”, line 166, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File “/home/goldin/miniconda3/lib/python3.7/site-packages/torch/autograd/init.py”, line 99, in backward
allow_unreachable=True) # allow_unreachable flag
File “/home/goldin/miniconda3/lib/python3.7/site-packages/torch/utils/data/_utils/signal_handling.py”, line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 4452) is killed by signal: Killed.
This is replicable. It looks suspiciously like a memory leak since the first 86 epochs complete successfully.
The training is taking about 3 minutes per epoch, so it takes about four and a half hours for the problem to appear.
Is there a way to turn off the _error_if_any_worker_fails() flag?
Can you offer suggestions for a work around?
Should this be raised as an issue on GitHub?
Thank you!