I’m trying to create a “simple” model that takes a standard (3-channel) 36x36 image and outputs a probability that the image contains a certain object of interest.
I’ve found a simple model (I don’t remember where, can’t credit), I adjusted the parameters to fit our needs. Since we’re planning on using C++, I’m using tracing to load this model
This is my Pytorch model (Python):
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 32, kernel_size=3, stride=1)
self.conv2 = torch.nn.Conv2d(32, 64, kernel_size=3, stride=1)
self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = torch.nn.Linear(64 * 7 * 7, 128)
self.fc2 = torch.nn.Linear(128, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7)
x = torch.relu(self.fc1(x))
x = self.sigmoid(self.fc2(x))
return x.squeeze(1)
Since the model works on a “non-standard Pytorch” dataset, I had to write a custom dataset class:
(I’ll only include the overloaded get function, since it’s really the only “moving part”)
The dataset expects a “main” directory to contain two sub-directories “Positive” and “Negative”, each containing the appropriate images.
torch::data::Example<> get(const std::size_t index)
{
constexpr auto labels = 2;
const auto indexAdjusted = index / labels;
const auto labelIndex = indexAdjusted % labels;
const std::string_view labelName = labelIndex == 0 ?
negativeDirectoryName : positiveDirectoryName;
// `_bacteriaImageDirectory` is an `std::filesystem::path` to the "Main" directory
const auto directory = _bacteriaImageDirectory / labelName;
auto directoryIterator = std::filesystem::directory_iterator(directory);
std::advance(directoryIterator, indexAdjusted);
auto image = cv::imread(directoryIterator->path().string());
cv::cvtColor(image, image, cv::ColorConversionCodes::COLOR_BGR2RGB);
auto tensorImage = torch::from_blob(image.data, { 3, image.cols, image.rows }, torch::kByte)
.to(torch::kFloat32) / 255.0f;
const auto tensorLabel = torch::tensor(static_cast<float>(labelIndex), torch::kFloat32);
return { tensorImage.clone(), tensorLabel };
};
This is my training loop, currently I run the training on 2160 images:
// Since `model` is a loaded "jit" module, I have to manually convert the module parameters
// to a valid type that can be accepted by `torch::optim::Adam`
std::vector<torch::Tensor> modelParameters;
modelParameters.reserve(model.parameters().size());
std::transform(model.parameters().begin(), model.parameters().end(),
std::back_insert_iterator(modelParameters),
[](const auto& p)
{
return p;
});
auto optimizer = torch::optim::Adam(modelParameters);
for(const auto& [image, label] : *dataLoader)
{
optimizer.zero_grad();
const auto output = model.forward({image}).toTensor();
const auto prediction = output.item<float>();
auto loss = torch::nn::functional::binary_cross_entropy(output, label);
loss.backward();
optimizer.step();
std::clog
<< "Loss: " << loss.item<double>()
<< ", Prediction: " << prediction
<< ", Label: " << static_cast<std::uint32_t>(label.item<float>())
<< '\n';
};
Attached are plotted results of the training. I don’t have much experience working with neural networks, but I don’t think training is supposed to look like that
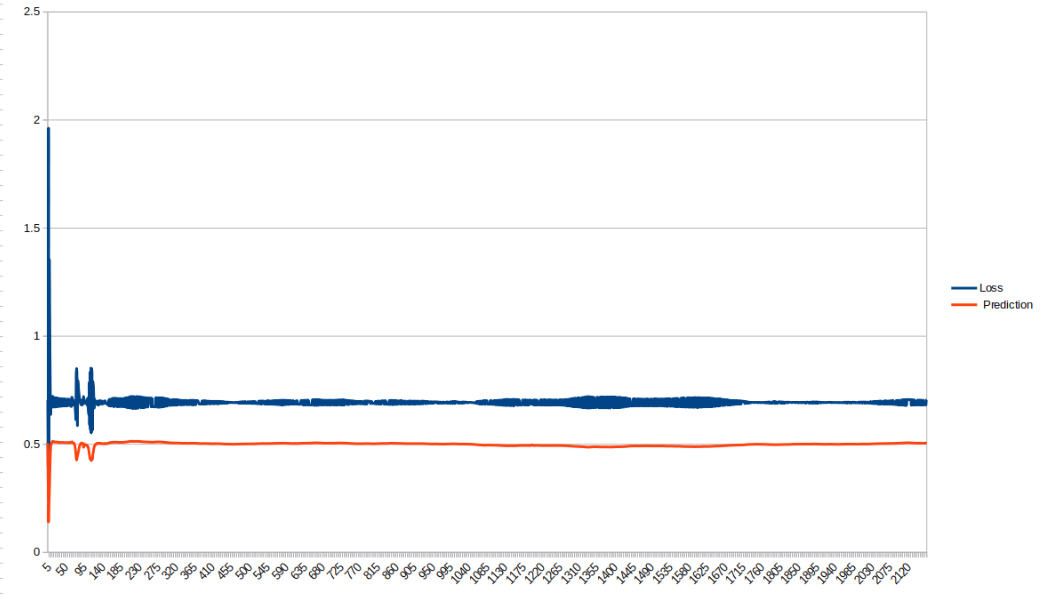
What am I missing? I’ve been stuck here for a while, any help is very appreciated