Hello,
I’m working on Conditional GAN to generate medical images and for testing purpose I ran the code on an resized image of 128x128 for 7500 epoch and this is working fine. But now when I change the code to train on a resized image of 512x512, The noise image generated on the first epoch is not being updated. I have no idea what’s going wrong.
Code for 128x128 image feed:
1. Loading the data :
train_transform = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
train_dataset = datasets.ImageFolder(root=‘data/KB_Images/’, transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=2, shuffle=True)
2. GAN Architecture :
def weights_init(m):
classname = m.class.name
if classname.find(‘Conv’) != -1:
torch.nn.init.normal_(m.weight, 0.0, 0.02)
elif classname.find(‘BatchNorm’) != -1:
torch.nn.init.normal_(m.weight, 1.0, 0.02)
torch.nn.init.zeros_(m.bias)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_conditioned_generator =nn.Sequential(nn.Embedding(3, 100),
nn.Linear(100, 16))
self.latent =nn.Sequential(nn.Linear(100, 4*4*512),
nn.LeakyReLU(0.2, inplace=True))
self.model =nn.Sequential(nn.ConvTranspose2d(513, 64*8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(64*8, 64*4, 4, 2, 1,bias=False),
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(64*4, 64*2, 4, 2, 1,bias=False),
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(64*2, 64*1, 4, 2, 1,bias=False),
nn.BatchNorm2d(64*1, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(64*1, 3, 4, 2, 1, bias=False),
nn.Tanh())
def forward(self, inputs):
noise_vector, label = inputs
label_output = self.label_conditioned_generator(label)
label_output = label_output.view(-1, 1, 4, 4)
latent_output = self.latent(noise_vector)
latent_output = latent_output.view(-1, 512,4,4)
concat = torch.cat((latent_output, label_output), dim=1)
image = self.model(concat)
#print(image.size())
return image
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_condition_disc = nn.Sequential(nn.Embedding(3, 100),
nn.Linear(100, 3*128*128))
self.model = nn.Sequential(nn.Conv2d(3, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64*2, 4, 3, 2, bias=False),
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*2, 64*4, 4, 3,2, bias=False),
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*4, 64*8, 4, 3, 2, bias=False),
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(),
nn.Dropout(0.4),
nn.Linear(9216, 1),
nn.Sigmoid()
)
def forward(self, inputs):
img, label = inputs
label_output = self.label_condition_disc(label)
label_output = label_output.view(-1, 3, 128, 128)
concat = torch.cat((img, label_output), dim=-1)
#print(concat.size())
output = self.model(concat)
return output
def noise(n, n_features=128): # this used to be 128
return Variable(torch.randn(n, n_features)).to(device)
3. Optimizer and Losses :
device = ‘cuda’
generator = Generator().to(device)
generator.apply(weights_init)
discriminator = Discriminator().to(device)
discriminator.apply(weights_init)
learning_rate = 0.0001
G_optimizer = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
images =
test_noise = noise(100)
adversarial_loss = nn.BCELoss()
def generator_loss(fake_output, label):
gen_loss = adversarial_loss(fake_output, label)
#print(gen_loss)
return gen_loss
def discriminator_loss(output, label):
disc_loss = adversarial_loss(output, label)
return disc_loss
4. Training :
num_epochs = 7500
for epoch in range(1, num_epochs+1):
D_loss_list, G_loss_list = [], []
g_error, d_error=0.0, 0.0
print("Epoch :",epoch)
for index, (real_images, labels) in enumerate(train_loader):
D_optimizer.zero_grad()
real_images = real_images.to(device)
labels = labels.to(device)
labels = labels.unsqueeze(1).long()
real_target = Variable(torch.ones(real_images.size(0), 1).to(device))
fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))
D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)
# print(discriminator(real_images))
#D_real_loss.backward()
noise_vector = torch.randn(real_images.size(0), 100, device=device)
noise_vector = noise_vector.to(device)
generated_image = generator((noise_vector, labels))
output = discriminator((generated_image.detach(), labels))
D_fake_loss = discriminator_loss(output, fake_target)
# train with fake
#D_fake_loss.backward()
D_total_loss = (D_real_loss + D_fake_loss) / 2
D_loss_list.append(D_total_loss)
D_total_loss.backward()
D_optimizer.step()
# Train generator with real labels
G_optimizer.zero_grad()
G_loss = generator_loss(discriminator((generated_image, labels)), real_target)
G_loss_list.append(G_loss)
G_loss.backward()
G_optimizer.step()
g_error += G_loss
d_error += D_total_loss
if index%15 ==0 :
vutils.save_image(real_images, '%s/real_samples.png' % "./results_epochs_7500", normalize = True)
fake = generator((noise_vector,labels))
vutils.save_image(fake.data, '%s/fake_samples_epoch_%03d.png' % ("./results_epochs_7500", epoch), normalize = True)
print('Epoch {}: g_loss: {:.8f} d_loss: {:.8f}\r'.format(epoch, g_error/index, d_error/index))
img = generator((noise_vector,labels)).cpu().detach()
# if epoch%100==0:
# for i in range(img.shape[0]):
# vutils.save_image(img[i], '%s/fake_samples_epoch_%03d_img_%01d.png' % ("./results", epoch,i), normalize = True)
img = make_grid(img)
images.append(img)
print(‘Training Finished’)
torch.save(generator.state_dict(), ‘Conditional-GAN.pth’)
frames =
for i in range(1,len(images)+1):
image = imageio.v2.imread(f’%s/fake_samples_epoch_%03d.png’% (“./results_epochs_7500”, i))
frames.append(image[:500])
print(f’%s/fake_samples_epoch_%03d.png’% (“./results_epochs_7500”, i))
imageio.mimsave(‘./progress.gif’, # output gif
frames, # array of input frames
fps = 7) # optional: frames per second
Real Sample Used for Training:
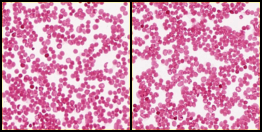
Epoch 1 Noise Image :

Epoch 6000 Noise Image :
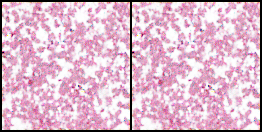
Below is Code for 512x512 Image feed :
train_transform = transforms.Compose([
transforms.Resize((512,512)),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
train_dataset = datasets.ImageFolder(root=‘data/KB_Images/’, transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=1, shuffle=True)
3. Optimizer and Losses :
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal_(m.weight, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
torch.nn.init.normal_(m.weight, 1.0, 0.02)
torch.nn.init.zeros_(m.bias)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_conditioned_generator = nn.Sequential(
nn.Embedding(3, 100),
nn.Linear(100, 256)) # Changed from 16 to 256
# Initial generator from latent space
self.latent = nn.Sequential(
nn.Linear(100, 16*16*512),
nn.LeakyReLU(0.2, inplace=True))
# Generator model definition
self.model = nn.Sequential(
nn.ConvTranspose2d(513, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 32, 4, 2, 1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.ConvTranspose2d(32, 3, 4, 2, 1, bias=False),
nn.Tanh())
def forward(self, inputs):
noise_vector, label = inputs
label_output = self.label_conditioned_generator(label)
label_output = label_output.view(-1, 1, 16, 16) # Correctly reshaped now
latent_output = self.latent(noise_vector)
latent_output = latent_output.view(-1, 512, 16, 16)
concat = torch.cat((latent_output, label_output), dim=1)
image = self.model(concat)
return image
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_condition_disc = nn.Sequential(nn.Embedding(3, 100),
nn.Linear(100, 3*512*512)) # Adjusted for 512x512 resolution
self.model = nn.Sequential(
nn.Conv2d(6, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(),
nn.Dropout(0.4),
nn.Linear(524288, 1), # Updated to match the correct number of features
nn.Sigmoid()
)
def forward(self, inputs):
img, label = inputs
label_output = self.label_condition_disc(label)
label_output = label_output.view(-1, 3, 512, 512)
concat = torch.cat((img, label_output), dim=1)
output = self.model(concat)
return output
def noise(n, n_features=512): # this used to be 128
return Variable(torch.randn(n, n_features)).to(device)
device = ‘cuda:1’
generator = Generator().to(device)
generator.apply(weights_init)
discriminator = Discriminator().to(device)
discriminator.apply(weights_init)
learning_rate = 0.0002
G_optimizer = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
images =
test_noise = noise(512) # This used ti be 100
adversarial_loss = nn.BCELoss()
def generator_loss(fake_output, label):
gen_loss = adversarial_loss(fake_output, label)
#print(gen_loss)
return gen_loss
def discriminator_loss(output, label):
disc_loss = adversarial_loss(output, label)
return disc_loss
4. Training :
num_epochs = 10000
for epoch in range(1, num_epochs + 1):
D_loss_list, G_loss_list = [], []
g_error, d_error=0.0, 0.0
print("Epoch :",epoch)
for index, (real_images, labels) in enumerate(train_loader):
D_optimizer.zero_grad()
real_images = real_images.to(device)
labels = labels.to(device)
labels = labels.unsqueeze(1).long()
real_target = Variable(torch.ones(real_images.size(0), 1).to(device))
fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))
D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)
# print(discriminator(real_images))
#D_real_loss.backward()
noise_vector = torch.randn(real_images.size(0), 100, device=device)
noise_vector = noise_vector.to(device)
generated_image = generator((noise_vector, labels))
output = discriminator((generated_image.detach(), labels))
D_fake_loss = discriminator_loss(output, fake_target)
# train with fake
#D_fake_loss.backward()
D_total_loss = (D_real_loss + D_fake_loss) / 2
D_loss_list.append(D_total_loss)
D_total_loss.backward()
D_optimizer.step()
# Train generator with real labels
G_optimizer.zero_grad()
G_loss = generator_loss(discriminator((generated_image, labels)), real_target)
G_loss_list.append(G_loss)
G_loss.backward()
G_optimizer.step()
g_error += G_loss
d_error += D_total_loss
if index%15 ==0 :
vutils.save_image(real_images, '%s/real_samples.png' % "./results_epochs_10000_512x512", normalize = True)
fake = generator((noise_vector,labels))
vutils.save_image(fake.data, '%s/fake_samples_epoch_%03d.png' % ("./results_epochs_10000_512x512", epoch), normalize = True)
print('Epoch {}: g_loss: {:.8f} d_loss: {:.8f}\r'.format(epoch, g_error/index, d_error/index))
img = generator((noise_vector,labels)).cpu().detach()
if epoch%100==0:
for i in range(img.shape[0]):
vutils.save_image(img[i], '%s/fake_samples_epoch_%03d_img_%01d.png' % ("./results_epochs_10000_512x512", epoch,i), normalize = True)
img = make_grid(img)
images.append(img)
print(‘Training Finished’)
torch.save(generator.state_dict(), ‘Conditional-GAN.pth’)
frames =
for i in range(1,len(images)+1):
image = imageio.v2.imread(f'%s/fake_samples_epoch_%03d.png'% ("./results_epochs_10000_512x512", i))
frames.append(image[:500])
print(f'%s/fake_samples_epoch_%03d.png'% ("./results_epochs_10000_512x512", i))
imageio.mimsave(‘./progress.gif’, # output gif
frames, # array of input frames
fps = 7) # optional: frames per second
Real Sample Used for Training:
Epoch 1 Noise Image :
Epoch 2000 Noise Image :
Below is the loss output of both Generator and Discriminator
Epoch : 1
Epoch 1: g_loss: 1.32907557 d_loss: 42.10420227
Epoch : 2
Epoch 2: g_loss: 0.00000000 d_loss: 50.18867874
Epoch : 3
Epoch 3: g_loss: 0.00000000 d_loss: 50.18867874
Epoch : 4
Epoch 4: g_loss: 0.00000000 d_loss: 50.18867874
Epoch : 5
Epoch 5: g_loss: 0.00000000 d_loss: 50.18867874
Epoch : 6
Epoch 6: g_loss: 0.00000000 d_loss: 50.18867874
Epoch : 7
Epoch 7: g_loss: 0.00000000 d_loss: 50.18867874
Both G and D are being constant for all the epoch.
Can you please let me know where make the changes so the model can be trained properly on a 512x512 image


