Hi all!
I have a autograd and distributed training problem using PyTorch. It is a NLP problem. I want to design a neural network like the following figure.
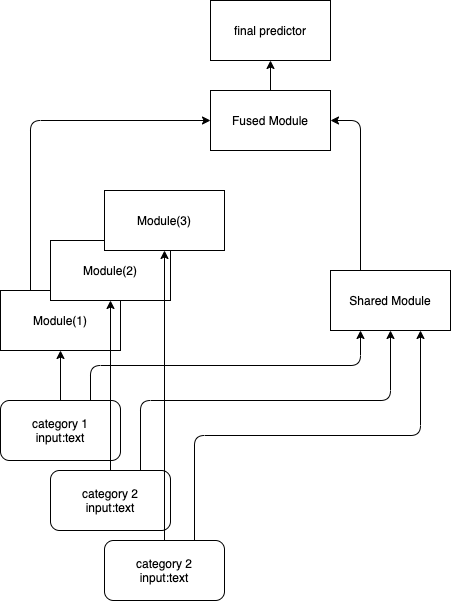
My dataset contains 50 kinds of text data. Each kind of text data has its own distribution. I want to use
modules of same architecture but different weight parameters. So each module can learn distribution of its related data input. Just like the left part of the figure.
What’s more, I want to use a module to capture some common features shared by different kinds of input data. (right part of the figure)
Now I do it like this. For modules of same architecture but different weights (left part of the figure), I use a nn.ModuleList. For example, if there are 50 kinds of data. I initialize 50 modules. category is a category list. The actual network is series of pytorch modules and is more complex than the figure and the demo code.
self.blocks = nn.ModuleList([
Block(...)
for i in range(len(category))
])
and for forward() method, I do it like this. I just iterate the batch and use different module defined in the above nn.ModuleList.
block_result_list = []
for i, category in enumerate(batch['category'].split(1)):
text_ids = batch['input_text']
text_embed = self.embed(text_ids[i])
x = self.blocks[category](text_embed)
block_result_list.append(x)
block_result = torch.cat(block_result_list)
batch['category'] is category info of one batch and batch['input_text'] is training text input.
I use HuggingFace accelerate for distributed training. However, when I use distributed training. I got the following error.
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by passing the keyword argument `find_unused_parameters=True` to `torch.nn.parallel.DistributedDataParallel`, and by
making sure all `forward` function outputs participate in calculating loss.
There may exists some unused parameters in forward pass because in every batch not all ModuleList may be involved. It depends on this batch of input. If this batch of input contains all categories, then all parameters are used.
If I set find_unused_parameters=True, the the output accuracy is much lower than expected.
If I do not use distributed training, just use one gpu, the output accuracy is correct.
So anybody has any ideas on how to design distributed training network of different modules conditioned on different distributions?