Hello,
I am training a Siamese network with Binary Cross Entropy Loss and calculating classification accuracy.
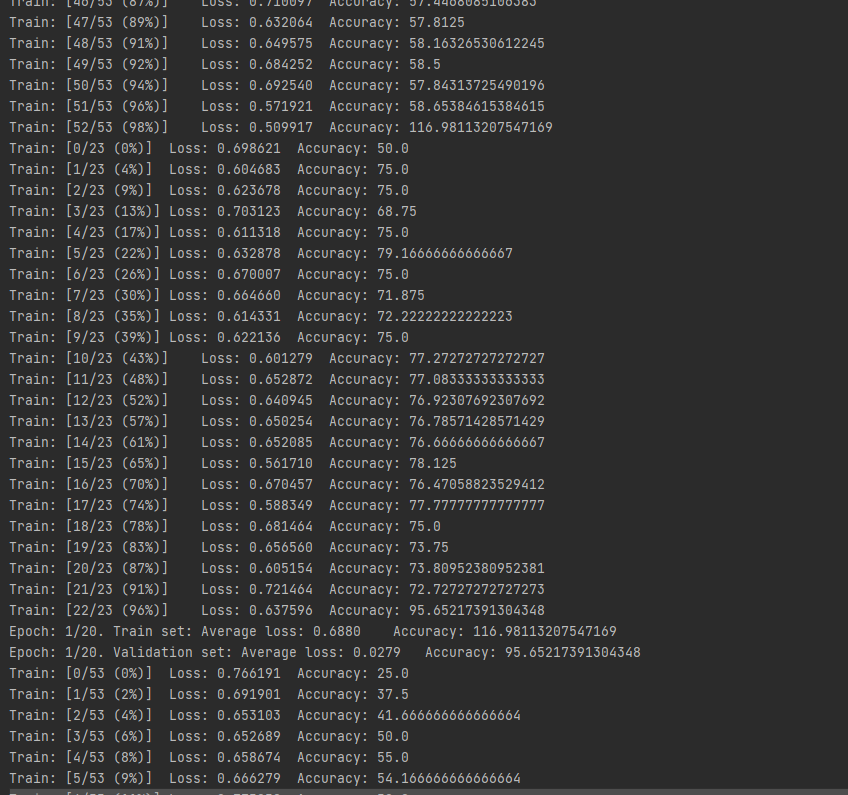
I have more than 100 % training accuracy at the end of each epoch. I am not able to fix this.
Following is the screenshot of the issue. (Please look at Epoch 1/20 : Accuracy : 116.98)
Following is the code snippet of train epoch and fit function:
def fit(train_loader, val_loader, model, loss_fn, optimizer, scheduler, n_epochs, cuda, log_interval, metrics,
start_epoch=0, message=None) -> object:
"""
Loaders, model, loss function and metrics should work together for a given task,
i.e. The model should be able to process data output of loaders,
loss function should process target output of loaders and outputs from the model
Examples: Classification: batch loader, classification model, NLL loss, accuracy metric
Siamese network: Siamese loader, siamese model, contrastive loss
Online triplet learning: batch loader, embedding model, online triplet loss
"""
for epoch in range(0, start_epoch):
scheduler.step()
#log_data['epoch'] = []
#log_data['train_losses'] = []
for epoch in range(start_epoch, n_epochs):
#log_data['epoch'].append(epoch)
scheduler.step()
# Train stage
train_loss, metrics = train_epoch(train_loader, model, loss_fn, optimizer, cuda, log_interval, metrics)
#log_data['train_loss'].append(train_loss)
message = 'Epoch: {}/{}. Train set: Average loss: {:.4f}'.format(epoch + 1, n_epochs, train_loss)
for metric in metrics:
message += '\t{}: {}'.format(metric.name(), metric.value())
val_loss, metrics = test_epoch(val_loader, model, loss_fn, cuda, metrics, log_interval)
val_loss /= len(val_loader)
message += '\nEpoch: {}/{}. Validation set: Average loss: {:.4f}'.format(epoch + 1, n_epochs,
val_loss)
for metric in metrics:
message += '\t{}: {}'.format(metric.name(), metric.value())
print(message)
def train_epoch(train_loader, model, loss_fn, optimizer, cuda, log_interval, metrics):
for metric in metrics:
metric.reset()
model.train()
losses = []
total_loss = 0
for batch_idx, ((x0, x1), y) in enumerate(train_loader):
x0, x1, y_true = x0.cpu(), x1.cpu(), y.cpu()
optimizer.zero_grad()
output1, output2 = model(x0, x1)
p_dist = torch.nn.PairwiseDistance(keepdim=True)
dy = p_dist(output1, output2)
dy = torch.nan_to_num(dy)
y_true = torch.nan_to_num(y_true)
'''2 lines indicated the normalization of dy to 0 and 1 by dividing it with max value'''
maximum_dy = torch.max(dy)
maximum_dy = torch.nan_to_num(maximum_dy)
dy = dy/maximum_dy
maximum_y_true = torch.max(y_true)
maximum_y_true = torch.nan_to_num(maximum_y_true)
y_true = y_true/maximum_y_true
dy = torch.squeeze(dy, 1)
input_dy = torch.empty(dy.size(0), 2)
input_dy[:, 0] = 1 - dy
input_dy[:, 1] = dy
y_true_2 = torch.zeros(dy.size(0), 2)
y_true_2[range(y_true_2.shape[0]), y_true.long()] = 1
m = nn.Sigmoid()
loss = loss_fn(m(input_dy), y_true_2)
loss.backward()
optimizer.step()
losses.append(loss.item())
total_loss += loss.item()
input_dy_metric = torch.round(input_dy)
for metric in metrics:
metric(input_dy_metric, y_true_2)
for metric in metrics:
metric.total = (batch_idx+1)*y_true_2.shape[0]
if batch_idx % log_interval == 0:
message = 'Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx, len(train_loader),
100. * batch_idx / len(train_loader), np.mean(losses))
for metric in metrics:
message += '\t{}: {}'.format(metric.name(), metric.value())
print(message)
losses = []
total_loss /= (batch_idx + 1)
return total_loss, metrics
Following is the Accuracy meric definition :
class Metric:
def __init__(self):
pass
def __call__(self, outputs, target, loss):
raise NotImplementedError
def reset(self):
raise NotImplementedError
def value(self):
raise NotImplementedError
def name(self):
raise NotImplementedError
class Binary_accuracy(Metric):
"""
Works with classification model
"""
def __init__(self):
self.correct = 0
self.total = 0
def __call__(self, input_dy_metric, y_true_2):
self.correct += (input_dy_metric == y_true_2).sum().float()/2
def reset(self):
self.correct = 0
self.total = 0
def value(self):
return 100 * float(self.correct) / self.total
#print(len(self.correct))
#print(self.total)
def name(self):
return 'Accuracy'
Any help is most appreciated.
Thank you in advance @ptrblck @eqy