Hi, I have a problem with MQRNN - multi-horizon quantile recurrent forecaster described here:
This is my code (short version):
import torch
from torch import nn
import torch.nn.functional as F
# Structure of neural network
class MQRNN(nn.Module):
def __init__(self, device, output_horizon = 5, n_products = 100, hidden_dim = 200, n_layers = 2):
self.device = device
super(MQRNN, self).__init__()
# encoded = hidden_dim*2
self.device = device
encoded = hidden_dim
self.output_horizon = output_horizon
self.n_products = n_products
self.output = output_horizon*n_products
self.n_layers = n_layers
self.hidden_dim = hidden_dim
# LAYERS
self.LSTM_encoding = nn.LSTM(self.n_products, self.hidden_dim, self.n_layers, batch_first=True).to(self.device)
self.MLPglob = nn.Linear(encoded, self.output+1).to(self.device)
self.MLPlocs = nn.ModuleList([nn.Linear(2, 3) for i in range(self.output)]).to(self.device)
def init_hidden(self, batch_size):
h0, c0 = (torch.zeros(self.n_layers, batch_size, self.hidden_dim),
torch.zeros(self.n_layers, batch_size, self.hidden_dim))
return h0, c0
def forward(self, x):
batch_size = x.size(0)
_, (h, c) = self.LSTM_encoding(x, self.init_hidden(batch_size))
# h, c = h[-1], c[-1]
# hc = torch.cat((h,c),1) # Concatenate, łączenie macierzy w jedną.
# hc = F.relu(hc)
# C = self.MLPglob(hc)
c = F.relu(h[-1])
C = self.MLPglob(c)
C = F.relu(C)
C, Ca = C[:,:-1], C[:,-1:]
C = C.view(-1,self.n_products,self.output_horizon)
output = torch.rand(self.n_products,self.output_horizon,batch_size,3).to(self.device) # 3 Quantyle -> dlatego 3 na końcu.
# output[0,0] = self.MLPlocs[0](torch.cat((C[:, 0, 0].view(-1,1), Ca),1))
for i in range(output.size(0)):
for j in range(output.size(1)):
output[i,j] = self.MLPlocs[output.size(1)*i+j](torch.cat((C[:, i, j].view(-1,1), Ca),1))
return output.permute(2,1,0,3)
# Loss function
def quantile_loss(y_pred, y_real):
"""
:param y_pred: 4 dimensions: batch_size, horizon, n_products, n_quantiles
:param y_real: 3 dimensions: batch_size, horizon, n_products
:return:
"""
y_pred = y_pred.permute(3,0,1,2)
loss = sum(sum(sum(2*(0.1*F.relu(y_real - y_pred[0])+0.9*F.relu(y_pred[0]-y_real)+
0.5*F.relu(y_real - y_pred[1]) + 0.5 * F.relu(y_pred[1] - y_real) +
0.9 * F.relu(y_real - y_pred[2]) + 0.1 * F.relu(y_pred[2] - y_real)))))
loss = loss/sum(sum(sum(y_real)))
return loss
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Sample data
x_1 = torch.FloatTensor([[[5000],[5043],[5015],[5100],[5109],[5150],[5183],[5222],[5243],[5259],[5298],
[5350],[5340],[5392],[5422],[5465],[5492],[5520],[5589],[5643]]]).to(device)
y_1 = torch.FloatTensor([[[5700],[5743],[5798],[5782],[5834]]]).to(device)
x_2 = torch.FloatTensor([[[5000],[5050],[5100],[5150],[5200],[5250],[5300],[5350],[5400],[5450],[5500],
[5550],[5600],[5650],[5700],[5750],[5800],[5850],[5900],[5950]]]).to(device)
y_2 = torch.FloatTensor([[[6000],[6050],[6100],[6150],[6200]]]).to(device)
x_3 = torch.FloatTensor([[[423],[413],[400],[392],[379],[354],[359],[352],[320],[298],[250],
[254],[243],[212],[2140],[201],[204],[254],[214],[355]]]).to(device)
y_3 = torch.FloatTensor([[[241],[231],[231],[221],[150]]]).to(device)
xx = torch.cat((x_1, x_3)).permute(2,1,0)
yy = torch.cat((y_1, y_3)).permute(2,1,0)
xx_2 = xx*10
yy_2 = yy*10
hidden_dim = 10
n_output = 5
n_products = xx.size(2)
model = MQRNN(device=device, n_products=n_products, n_layers=1,
output_horizon=n_output, hidden_dim=hidden_dim)
model.to(device)
ADAM = torch.optim.Adam(model.parameters(), lr=0.0126) # lr=100.0126
n_epochs = 1600
for epoch in range(n_epochs):
pred = model(xx)
loss = quantile_loss(pred, yy)
# ADAM.zero_grad()
# loss.backward()
# ADAM.step()
pred = model(xx_2)
loss += quantile_loss(pred, yy_2)
ADAM.zero_grad()
loss.backward()
ADAM.step()
if epoch % 100 == 0:
print('Epoch: {}/{}.............'.format(epoch, n_epochs), end=' ')
print("Loss: {:.4f}".format(loss.item()))
I have of course different real data, but on this sample my problem looks clearly.
First problem is that model learns very very slow, there is not any big decline of loss on the beginning (with normal learning rate e.g. 0.0126). In fact I need to set very big learning rate - 100 on the beginning to make learning faster. If I use normal learning rate results are similiar but it take a long time.
Second, and more important problem does not react to the structure of input data.
I gave two tensors, where second is the first times 10 as input data, and as you can see network get to some local minimum finding the same output for every input.
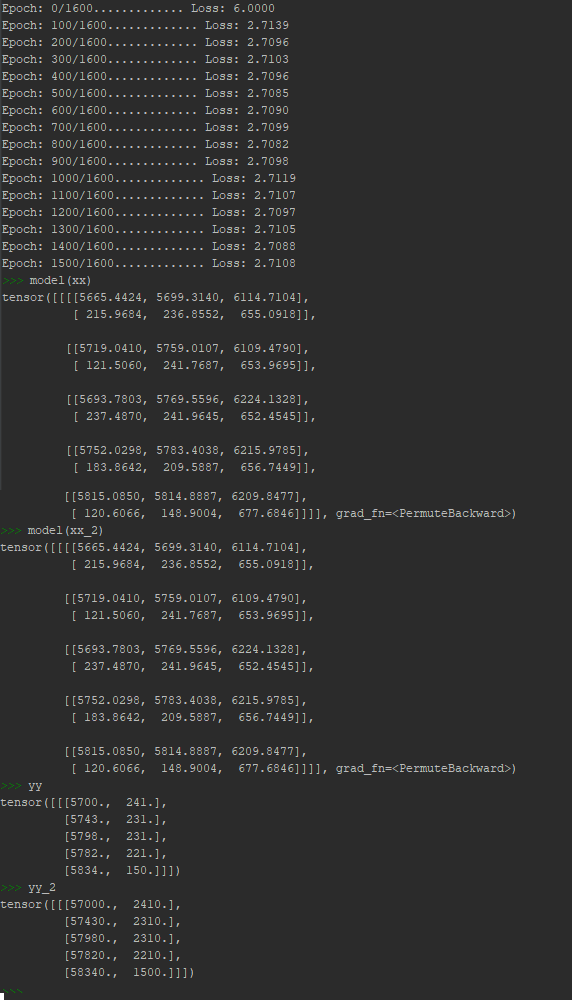
(as a new user I can upload only one image, I hope that it will be visible.)
How can I solve this problem to get reasonable predictions?