I am training a deep model with an LSTM and GNNs. It is a regression problem so the loss is MSE Loss. I am seeing that the loss becomes NaN after a few iterations. I turned on torch.autograd.set_detect_anomaly, and here is what I get:
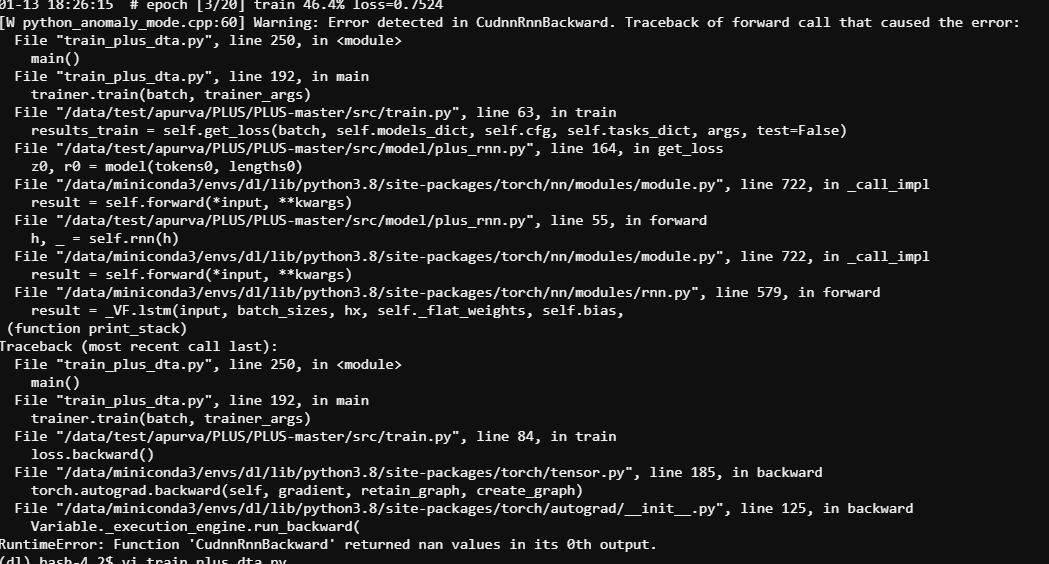
The code in question is:
…
…
order = torch.argsort(lengths, descending=True)
order_rev = torch.argsort(order)
x, lengths = x[order], lengths[order]
# feed-forward bidirectional RNN
self.rnn.flatten_parameters()
total_length = x.shape[1]
h = self.embed(x)
h = pack_padded_sequence(h, lengths, batch_first=True)
h, _ = self.rnn(h)
h = pad_packed_sequence(h, batch_first=True, total_length=total_length)[0][:, 1:-1][order_rev]
…
…
I inserted forward hooks, and checked the parameters after every training loop like so:
def nan_hook(self, inp, output):
if type(output) == torch.nn.utils.rnn.PackedSequence:
outputs = [output.data]
elif not isinstance(output, tuple):
if type(output[0]) == torch.nn.utils.rnn.PackedSequence:
outputs = [output.data]
else:
outputs = [output]
else:
if type(output[0]) == torch.nn.utils.rnn.PackedSequence:
outputs = [output[0].data]
else:
outputs = output
for i, out in enumerate(outputs):
nan_mask = torch.isnan(out)
if nan_mask.any():
print("In", self.__class__.__name__)
raise RuntimeError(f"Found NAN in output {i} at indices: ", nan_mask.nonzero(), "where:", out[nan_mask.nonzero()[:, 0].unique(sorted=True)])
inf_mask = torch.isinf(out)
if inf_mask.any():
print("In", self.__class__.__name__)
raise RuntimeError(f"Found INF in output {i} at indices: ", inf_mask.nonzero(), "where:", out[inf_mask.nonzero()[:, 0].unique(sorted=True)])
for submodule in model.modules():
submodule.register_forward_hook(nan_hook)
Checking for parameters after every training loop:
for model in self.models_dict["model"]:
for param in model.parameters():
if not torch.isfinite(param.data).all():
print("param data:", torch.isfinite(param.data).all())
None of these checks fire indicating that there are no NaNs in the data or in any of the parameters.
My machine configuration is:
NVIDIA-SMI 460.27.04
Driver: 460.27.04
CUDA 11.2
GPU: V100, 16GB
I am using python 3.8.5, and pytorch 1.6.0 and cudatoolkit 10.2.89
This problem started coming after IT upgraded the machine. I am trying to find out from IT what upgrade they did on the machine.
I tried upgrading to pytorch1.7 and cudatoolkit11.0, but that combination seems to be unstable and has its own share of problems.
I have searched on the forums, and have tried the usual techniques (reducing learning rate, adding L2 regularization etc), but those just move the problem around to a later point. Gradient clipping is also turned on. The problem never really goes away.
Any suggestions to debug will be very welcome.
Thanks,
Apurva