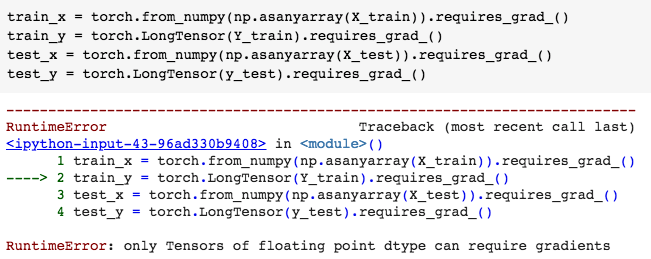
No, this isn’t correct. First, calling the .long() method on a LongTensor is a no-op (does nothing). Second, the train_y
are to be used as categorical class labels, so they have to be
a LongTensor.
First, could you clarify what version of pytorch you are using?
What type of data structure are your X_train, Y_train, etc.,
before you wrap them in numpy arrays?
Just to clean things up a little, I would (try to) convert directly
from your originalX_train, etc., to pytorch tensors.
(Please, in general, post text rather than screen-shots. It can then
be searched and copy-pasted.)
The main issue is that you neither need nor want gradients for
your data (neither training nor test). You use gradients for the
parameters of your model.
When you “train” your model you adjust the parameters of your
model so that they do a better job classifying your inputs. The
whole idea behind pytorch’s autograd facility is that it calculates
for you the gradients of your loss function with respect to your
model parameters so that you can use an optimization algorithm
such as gradient descent to “optimize” (change) those parameters
so that your model produces a lower loss function.
You don’t change the data you are training (or testing) with.
If you construct your model in the “standard” way, your model
parameters will automatically be flagged with requires_grad = True.
Note, a FloatTensor is (approximately) continuous, so it makes
sense to “do calculus” on it, i.e., calculate gradients.
But a LongTensor is made up of discrete (long) integers, so it
isn’t natural to “do calculus” on it, so pytorch doesn’t support requires_grad = True for LongTensors.
You should make your train_x and test_x “ordinary” FloatTensors (that will default to requires_grad = False),
and your train_y and test_yLongTensors (without .requires_grad_()) (that pytorch will force to have requires_grad = False).
Perhaps it would make sense to write a complete, runnable
script that generates some toy (random, if you choose) data,
packages that data in the appropriate pytorch tensors,
build a simple (one or two-layer) model, and pass one
batch of your input data through the model.
If you have trouble getting that to run, print out the types and
shapes of some of your tensors along the way, and post the
complete, runnable script, along with the output, and tell us
what problems you are having.