Hello. I am dealing with the multi-class segmentation.
I used to handle the binary class for semantic segmentation.
In the binary, I use the binary mask as the target.
However in the multi-class, it looks like I need some change.
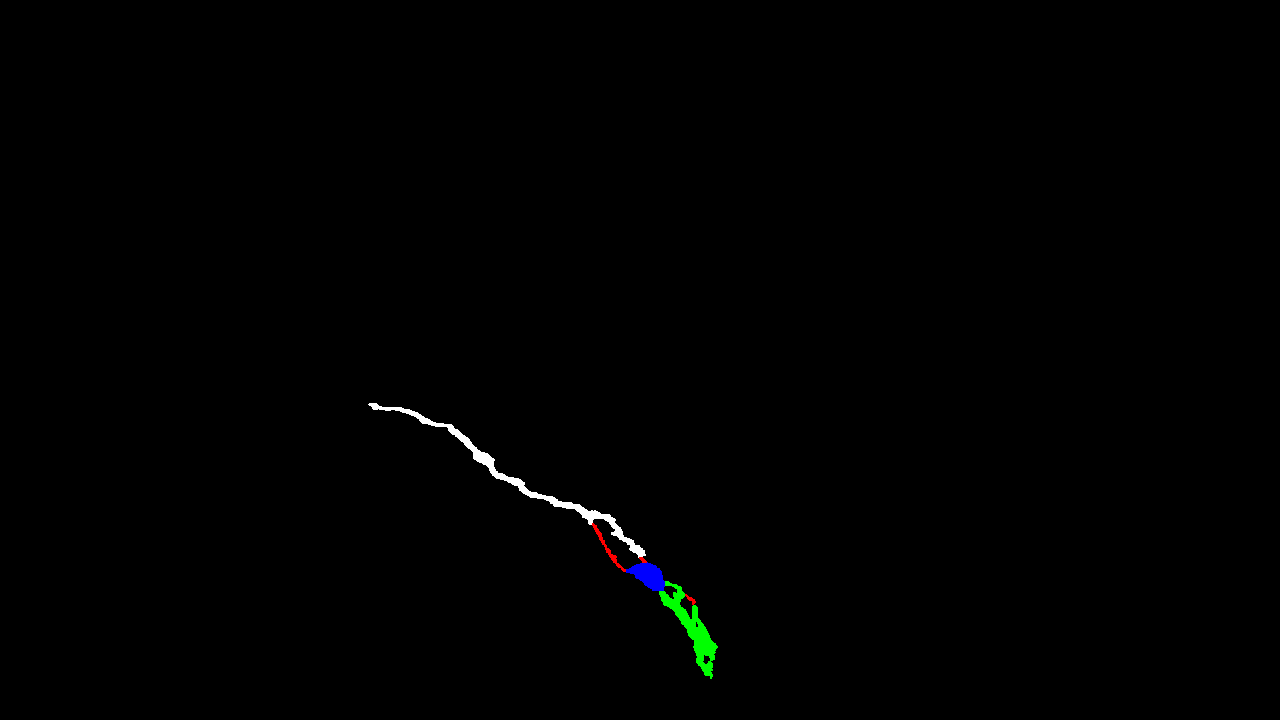
This is my mask.
I have 5 classes which are Red, Green,Blue, white and black.
My model output is the 5 channel.
self.fuse=conv_1(ch_in=112,ch_out=5)
I use this 5 classes with 3 channel image as 1 channel image use below code.
r,g,b=cv2.split(target_img)
r[r==255]=1
g[g==255]=2
b[b==255]=3
mask=r+g+b
mask[mask==6]=4
target_img=mask
After that I run the below train loop.
Because I read some article and they said I have to use one hot encoding for cross entropy loss.
self.criterion = nn.CrossEntropyLoss().to(self.device)
def run_train_loop(self, epochs):
# Run training
for epoch in range(epochs):
print('Epoch {}/{}'.format(epoch + 1, epochs))
print('-' * 10)
self.scheduler.step()
for param_group in self.optimizer.param_groups:
lr = param_group['lr']
print("Learning rate: " + str(lr))
running_loss = 0.0
running_score = 0.0
for batch_idx, (images, masks) in enumerate(self.train_data_loader):
# Obtain batches
images, masks = images.to(self.device), masks.to(self.device)
masks=masks.squeeze(1)
self.optimizer.zero_grad()
model= self.model.to(self.device)
output = model(images)
loss = self.criterion(output, masks.long())
However, my loss is 0 after some epoch. I have 2000 images and mask. So I think it is not the lack of data problem. I am not using the softmax function but I read some answer in this forum that it has already included in cross entropy function. If not I have to include it of course.
Also I am not sure that it is the correct way that the ground truth channel is 1 channel only. Becuase output of the model is 5 channel. Do you think I should change the my mask as 5 channel with 0 and 1? Or should my model output is the 5 channels, because 0 is background.
Also I am not sure that what is class mapping? Does it just decode the segmentation output for visualization? Or how can I put class information to the training process?
I am little bit confuse about it.
Thank you.