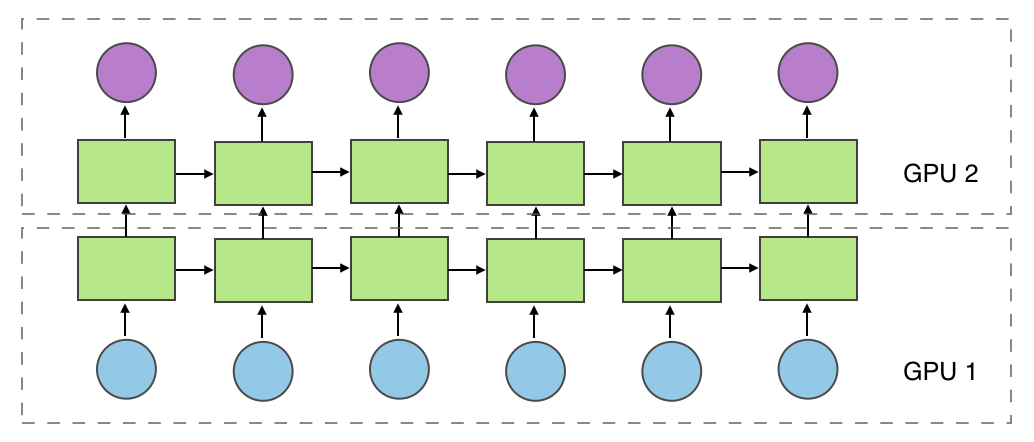
Hi,
My model is too large to fit into one GPU, so I split it into two GPUs. Part of the models are as follows:
cur_layer_input = []
for t in range(seq_len):
d1 = self.down1.cuda(self.device_ids[0])(img_seq_ring[:, t]).cuda(self.device_ids[0])
d2 = self.down2.cuda(self.device_ids[0])(d1)
cur_layer_input.append(d2.cuda(self.device_ids[1]))
I used DDP to wrap this model:
from torch.nn.parallel import DistributedDataParallel as DDP
model = DDP(model, device_ids=[device_ids[0]], find_unused_parameters=True).
However, errors occured:
File "xxx.py", line 141, in train_model
loss.backward()
File "/home/anaconda3/envs/VIBE/lib/python3.7/site-packages/torch/tensor.py", line 195, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/home/anaconda3/envs/VIBE/lib/python3.7/site-packages/torch/autograd/__init__.py", line 99, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: grad.device() == bucket_view.device() INTERNAL ASSERT FAILED at /pytorch/torch/csrc/distributed/c10d/reducer.cpp:206, please report a bug to PyTorch.
I do not know what bucket_view.device() is. So I do not know how to solve this problem.
Could you help me?
Thank you very much.