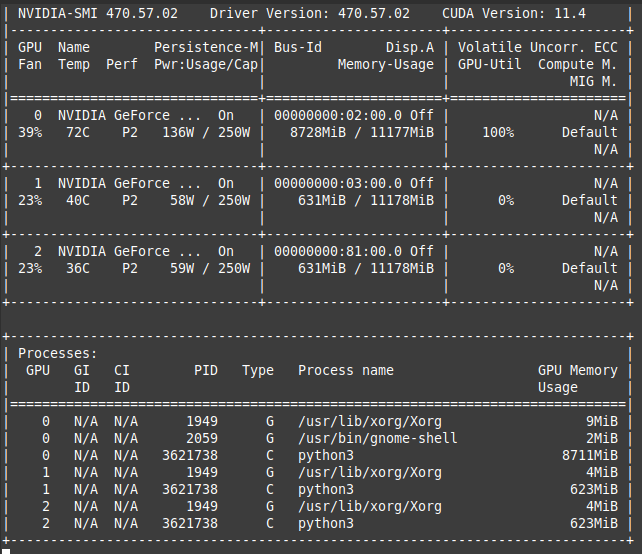
I am trying to train the coco dataset on a 3-gpu system. I put model in torch.nn.DataParallel but the dataloader can not spread the data between the gpus and it uses only the first gpu!
When I load all data into a python list and then in the epochs I read them from that python array, all 3 gpus work fine! It seems to be a problem of dataloader (or cocodetection class) but I don’t have a clue.
nn.DataParallel will clone the model onto al specified devices, split the input batch in dim0, and send each chunk to the corresponding device. It won’t do anything with your data loading. A good description is given in this blogpost. If you want to use load a subset of the data for each device, use DistributedDataParallel with the DistributedSampler, which would also yield a larger speedup.
Thank you ptrblck. Spliting the batch and sending them to multiple devices is all that I need, but it doesn’t do that. In each epoch I have a loop as below:
for images, targets in train_loader:
images = list(torchvision.transforms.ToTensor()(image).to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
...
After loading each batch I send them to cuda devices, but it utilizes only the first gpu. If instead of train_loader I use an array (already filled with the data), this code works with all gpus.
Sorry I don’t know how to reproduce it with random tensors, but this is exactly what I did (it’s just the training part):
(It won’t give any error and works smoothly but with just one gpu)
device = torch.device("cuda")
device_ids = [i for i in range(torch.cuda.device_count())]
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
256,
num_classes)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
model= torch.nn.DataParallel(model, device_ids=[0, 1, 2])
model.to(device)
model = model.cuda()
train_data = get_coco(path_to_data, "train", None)
train_loader = torch.utils.data.DataLoader( train_data
,batch_size=batch_size
,num_workers=num_workers
,collate_fn=collate_fn
)
for epoch in range(num_epochs):
model.train()
bj = 0
for images, targets in train_loader:
images = list(torchvision.transforms.ToTensor()(image).to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
# reduce losses over all GPUs for logging purposes
loss_dict_reduced = utils.reduce_dict(loss_dict)
losses_reduced = sum(loss for loss in loss_dict_reduced.values())
loss_value = losses_reduced.item()
if not math.isfinite(loss_value):
print("Loss is {}, stopping training".format(loss_value))
print(loss_dict_reduced)
sys.exit(1)
optimizer.zero_grad()
losses.backward()
optimizer.step()
One thing is strange for me that, the code gets all gpus engaged, because their memories are a little filled up, but not that much that could work!
When I train with one gpu I set batch_size=2 and for 3gpus I should set batch_size=6, but if I set that as 6, the code gives me gpu OOM error which shows that only one gpu is engaged with the data.
[I don’t know if that is related or not but I am using docker container to run the code! with` --gpus all` of course]