Whelp, there I go buying a second GPU for my Pytorch DL computer, only to find out that multi-gpu training doesn’t seem to work  Has anyone been able to get DataParallel to work on Win10?
Has anyone been able to get DataParallel to work on Win10?
One workaround I’ve tried is to use Ubuntu under WSL2, but that doesn’t seem to work in multi-gpu scenarios either…
Based on this post it seems that DDP is coming first to Windows (which should also be faster than nn.DataParallel if you are using a single process per GPU), while other data parallel utilities seem to be on the roadmap.
Hey @nickvu, I would expect DataParallel to work with Windows. What error did you see when using it?
Echoing @ptrblck’s comment, yep, Windows support for DDP (with only FileStore rendezvous and Gloo backend) will be included in v.17 as a beta feature. If you encountered any issue with it, please join the discussion here:
Hi @mrshenli!
The main issue was that there is no NCCL for Windows I think. So yes, the code with a DP-wrapped model would run, and the two GPUs would even show up as active, but the training time would be exactly the same as when using 1 GPU, leading me to think that it’s not really splitting the load…
Any advice on how to tackle it? I would honestly prefer to work with DataParallel since I’m on a single PC - DDP seems much more involved.
Thanks!
Hey @nickvu, thanks for sharing the details. DP is less efficient compared to DDP, as it needs to replicate the model in every iteration. And IIUC, currently there is no plan to improve DP performance. cc @VitalyFedyunin
So if perf is the main concern, DDP might be a better choice.
@mrshenli and @ptrblck
If NCCL is supported only in Linux and DDP uses NCCL, how would the support in Windows actually work? For example, I was training a network using detectron2 and it looks like the parallelization built in uses DDP and only works in Linux.
How would the upcoming support of DDP in Windows work (unless I’m mistaken it would likely not use NCCL)? Would the speeds be slower as compared to doing the same training on Linux?
Finally, how would using WSL2 compare to the native Windows support of DDP?
Currently, DDP can only run with GLOO backend.
For example, I was training a network using detectron2 and it looks like the parallelization built in uses DDP and only works in Linux.
MSFT helped us enabled DDP on Windows in PyTorch v1.7. Currently, the support only covers file store (for rendezvous) and GLOO backend. So when calling init_process_group on windows, the backend must be gloo, and init_method must be file. To run on a distributed environment, you can provide a file on a network file system. Please see this tutorial and search for win32 .
Would the speeds be slower as compared to doing the same training on Linux?
Yep, Gloo backend will be slower than NCCL.
Finally, how would using WSL2 compare to the native Windows support of DDP?
I am not aware of this. Let me ask MSFT experts to join the discussion. ![]()
@nickvu, glad to see you want use DDP on Windows. We will do a benchmark for DDP on Windows. At meantime we will compare the performance of DDP between on native Windows and WSL v2. Will update you with result here.
2 Likes
@nickvu, here is the result we compared. Please notice that the result is compared to Linux VM, not WSL
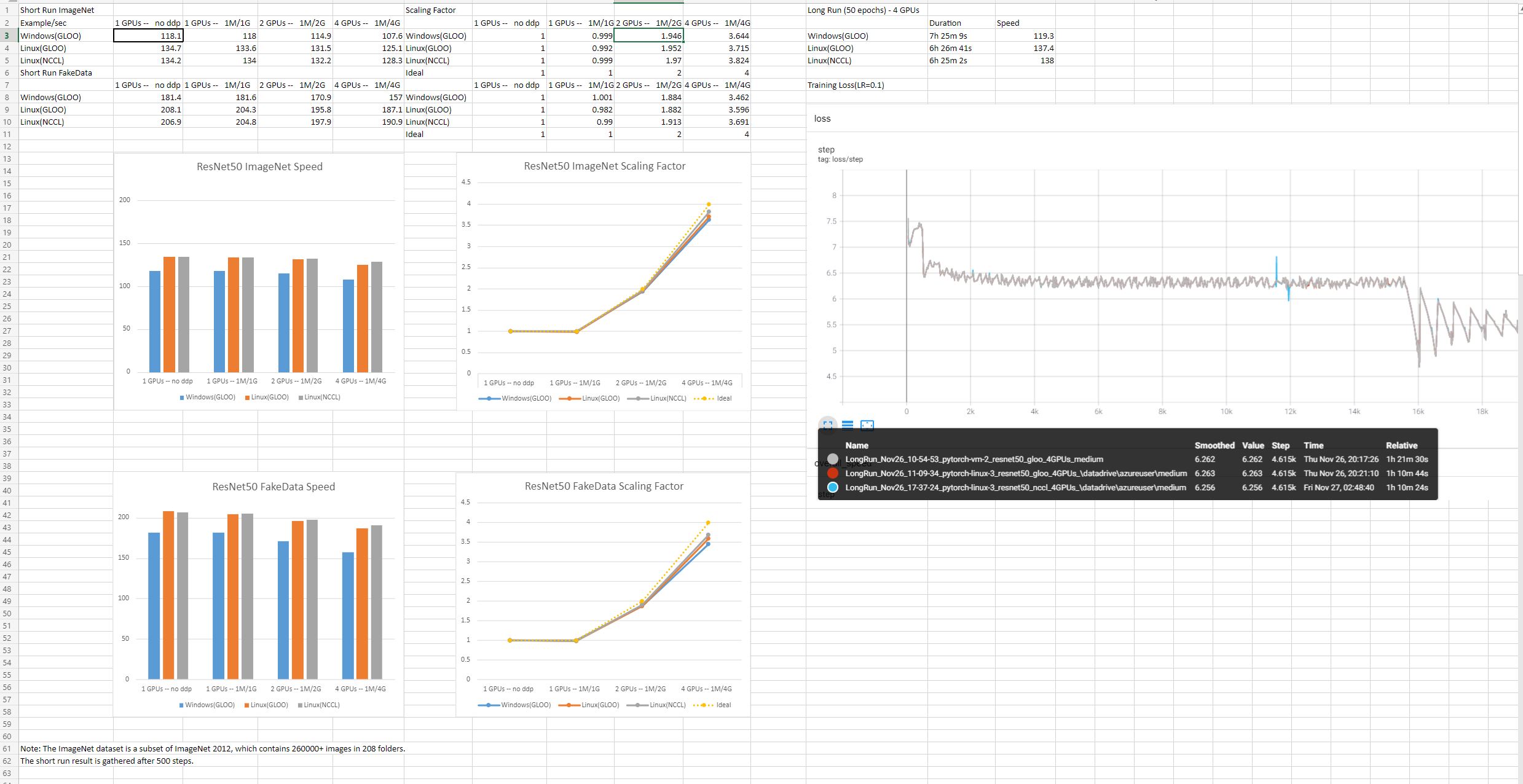
3 Likes
Thanks for posting this and showing the metrics.
I am wondering if anything has changed since the past. Can WSL2 do DDP now?
So I’m trying to run train_net.py in Windows. I have a machine with 4 GPUs. This works fine in Linux but not in Windows. In Windows I get:
raise RuntimeError(“No rendezvous handler for {}://”.format(result.scheme))
RuntimeError: No rendezvous handler for tcp://
Does this have anything to do with nccl vs gloo? Can I force a gloo backend to get DDP working in detectron2?
Are there changes I would have to make to get this working in Windows?
I believe it would involve changes to detectron2\engine\launch.py
Would it be something like:
dist.init_process_group(backend=“gloo”, init_method=file:///c:/libtmp/test.txt, world_size=world_size, rank=global_rank)
Thank you posting the benchmark results. I am trying to reproduce the same results ourselves in my Windows environment but I am not able to see the same speed-up you get. Are you using an open benchmark? Or even if you could give us a few pointers on the ImageNet algo, training set and parameters it would be very appreciated. Thank you!
Hi folks, can anyone provide any guidance/point me at any links so I can understand more of what happens when (GPU-enabled) PyTorch is run on Windows 10 with 2 GPUs? I am doing an NLP project using the HuggingFace libraries and when I run it I get the warning “UserWarning: PyTorch is not compiled with NCCL support” which I can understand from discussion in this thread is (still) to be expected on Windows until NCCL is available.
So I run the script to run training on my model and looking at the performance tab of Task Manager, both GPU 0 and GPU 1 jump from effectively 0 memory usage to approximately similar 18GB of 24B on each GPU. Should I expect that both GPUs get busy given the NCCL issue above? Both GPUs seem busy, so what is happening?
Any clues very much appreciated!!!
And by the way, it is not my machine, I am remoting into it so not an option to install Linux to avoid Windows 10. That said, the owner of the machine has said he is happy to temporarily physically remove one of the GPUs so at least I would have more certainty of what is going on with only 1 GPU on Windows.
Have physically unistalled one GPU so problem over I hope.
Could you share your windows multi-gpu training code? I can not training with multi-gpu with DDP
Has your code worked?
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
You can always use this in your train.py file to control which device is accessible to Pytorch.