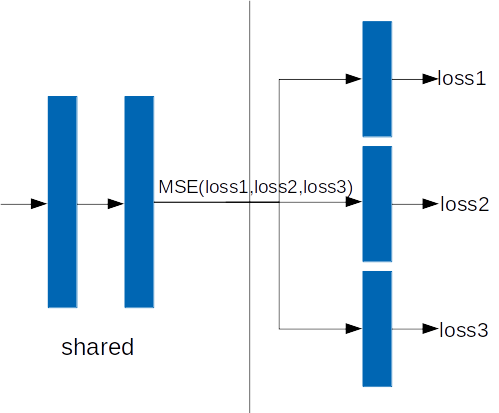
I want to propagate loss1, loss2 and loss3 to the output of the shared network and MSE(loss1,loss2,loss3) from the output of the shared network all the way back. The shared network and each of the action head networks have their own network classes and torch.optim.
But I’m getting this error during the second backward() call
“Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.”
How can I do this? What am I not understanding about how Pytorch performs backprop? Thanks.
You can combine the losses from all heads, and backprop that using a single optimizer that is initialized with all the parameters in your model (shared network and each of the action heads). Read more about backpropagating loss in multi-task learning architectures.
Thank you sir. I had tried that before but I couldn’t make my agent learn properly, so that’s why I was trying something different. Is there a good reference that explains how .backward() and .step() actually do their magic? This is the most difficult aspect of Pytorch for me to understand. Thanks.
You’re welcome! It can be a bit tricky to wrap your head around what’s happening at first under the hood, but very simply:
autograd creates a graph of all your model’s operations
when you call backward, it traverse this graph and collects gradients (using backpropagation). once it reaches the end of the graph, it is released from memory. that’s why you get the error on the second backward() call
when you call step(), every parameter is updated by the gradients collected in the backward() pass.