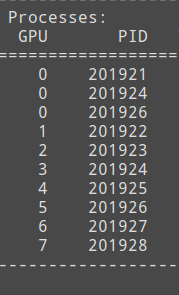
I use the torch.distributed.launch module to multi-processing my training program. Everything seems fine but I don’t know why some process in 1-N gpu will has another memory usage in GPU 0.
As depicted in the picture, the process in gpu4,6 have something in gpu0, this two usage are about 700+M memory. And sometimes other processes will also have similar behavior, but not all the other process will have memory usage in gpu0.
I don’t know why this thing happen? Since the memory unbalances, the training sometimes will be close due to 'out of memory error.
I agree this can be annoying. As you see not all processes initialize this context. Is there perhaps some path in your code that conditionally initialized some memory, or sets the CUDA device manually? We don’t have any facilities that I know of to point to the culprit here, aside from simply looking at code.