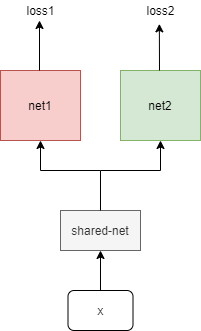
When the codes run to the line <loss2.backward()>, there will be an error “RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [128]] is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).”. I wonder if the two optimizer could have the same part ‘shared_net’
Thank you for your reply. I have tried loss1.backward(retain_graph=True), but there is the same error.
If I use the loss = loss1 + loss2 to optimize the net1, net2, shared-net with one optimizer, will the gradient update of net1 be affected by the loss2 of the net2 part?
Oh sorry I think I read a totally different thing.
The in-place computation means you modified a variable by manually changing its data. For example if you write w[7]=18 in the forward pass, in-place sums or similar things. Here you have a more elaborated explanation.
Would you mind to post the code of the networks? I may identify it visually.
Wrt your other question no. Think that the gradient of the sum depends on each term only. This way the shared network gets a proper optimization as the gradient will be optimized jointly. Otherwise the shard net gets their parameters updated, then the error from loss2 was computed with the previous weights and they kinda fight to optimize the problems separately
Hello, did you solve the problem? I have the same problem too! When there are multi loss items, and they share the same backbone, if sum all losses together, will one loss have an influence on other networks?