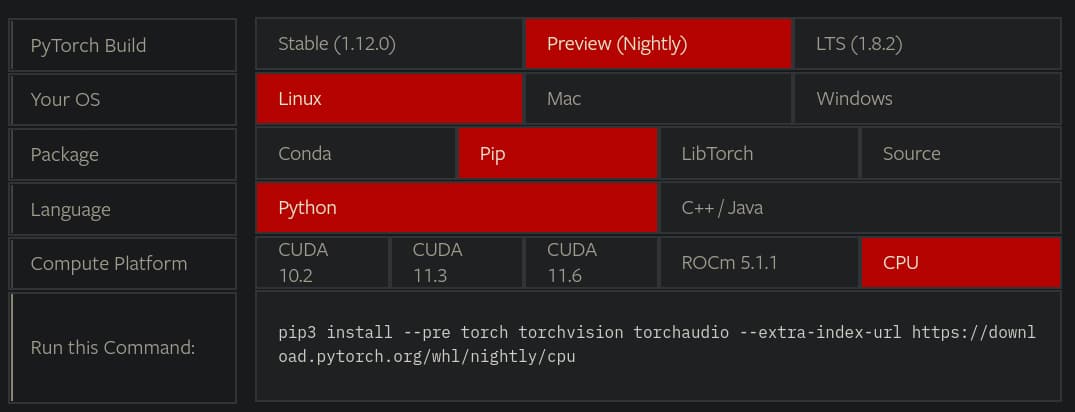
Greetings,
I am attempting to implement the A3C algorithm - requiring that there be a pool of agents, each undertaking a relatively distinct trajectory through the environment. This is accomplished by using the torch.multiprocessing module.
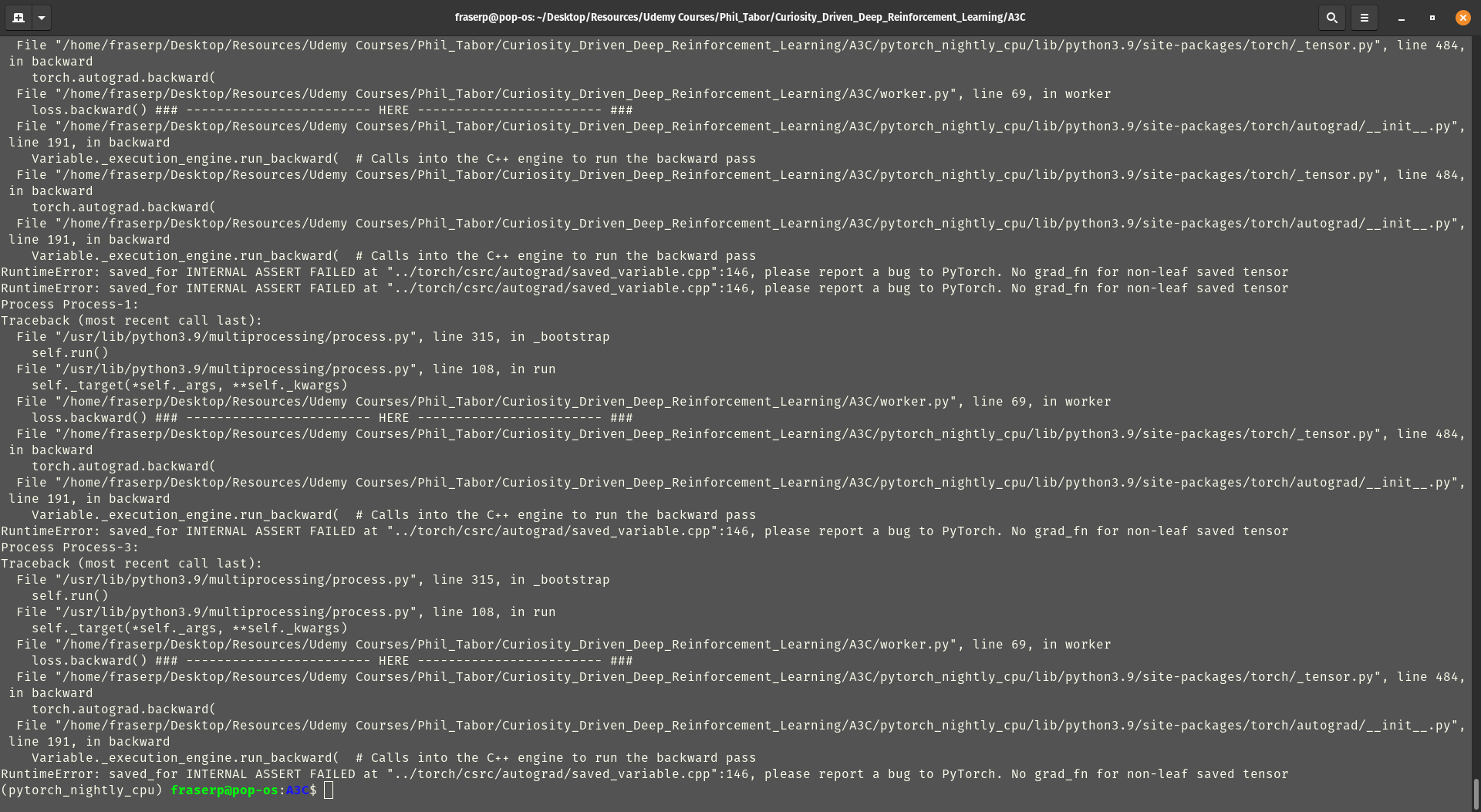
I am receiving a relatively cryptic error, requesting that I report a bug to Pytorch:
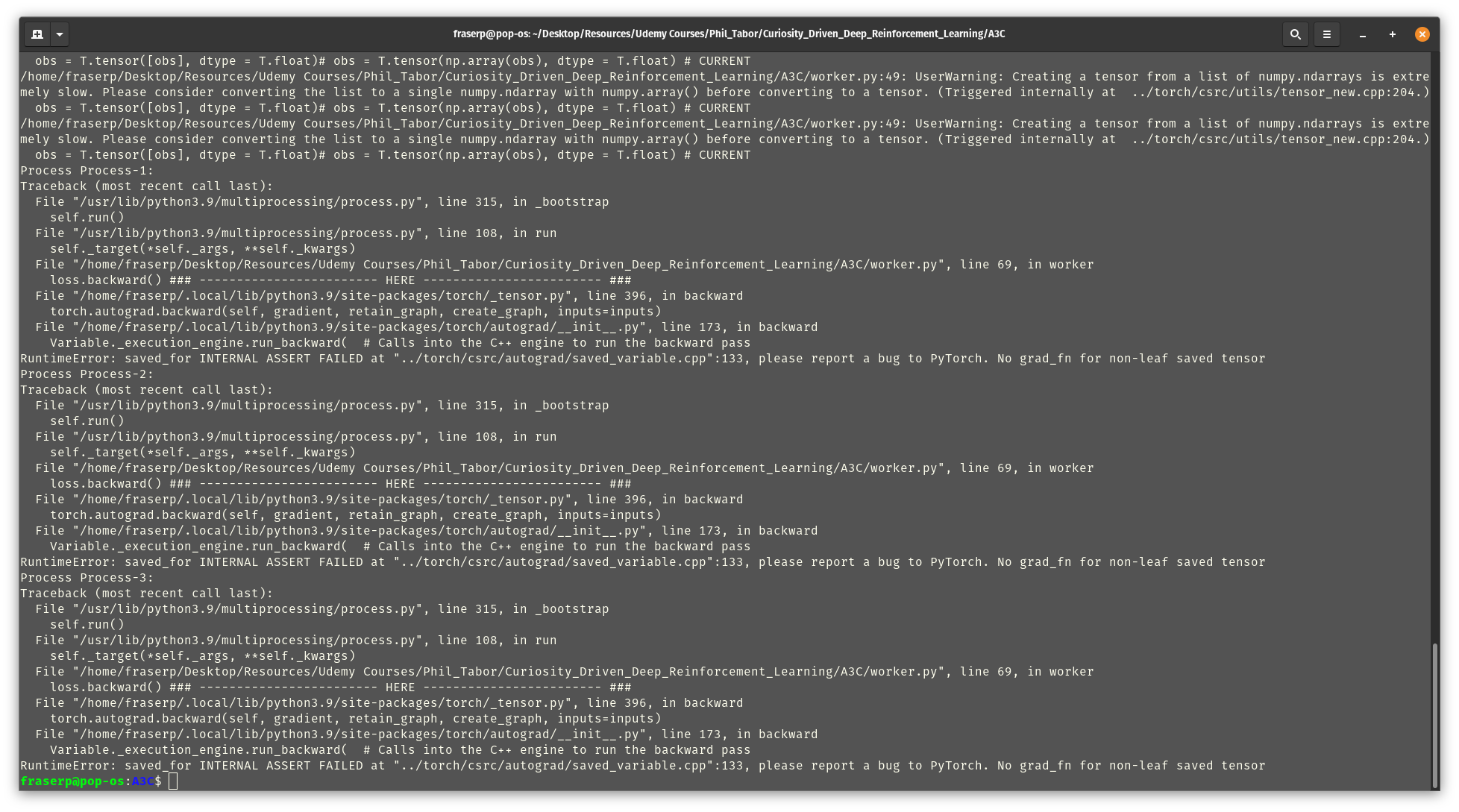
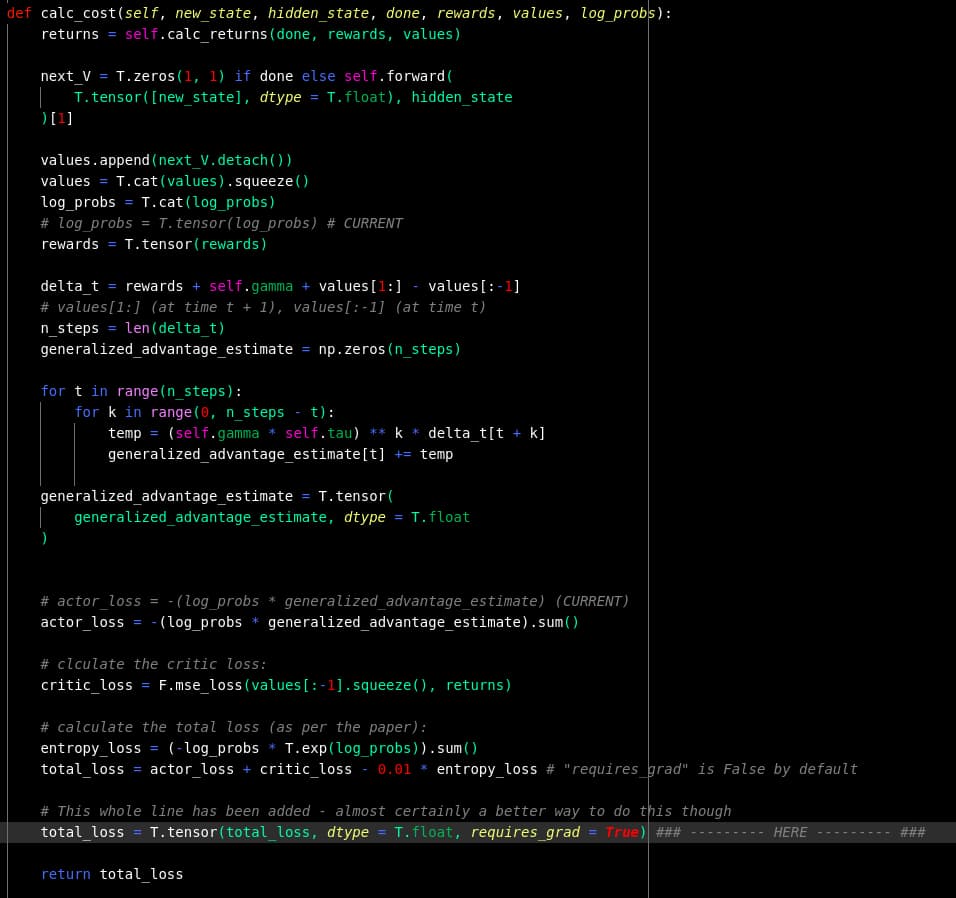
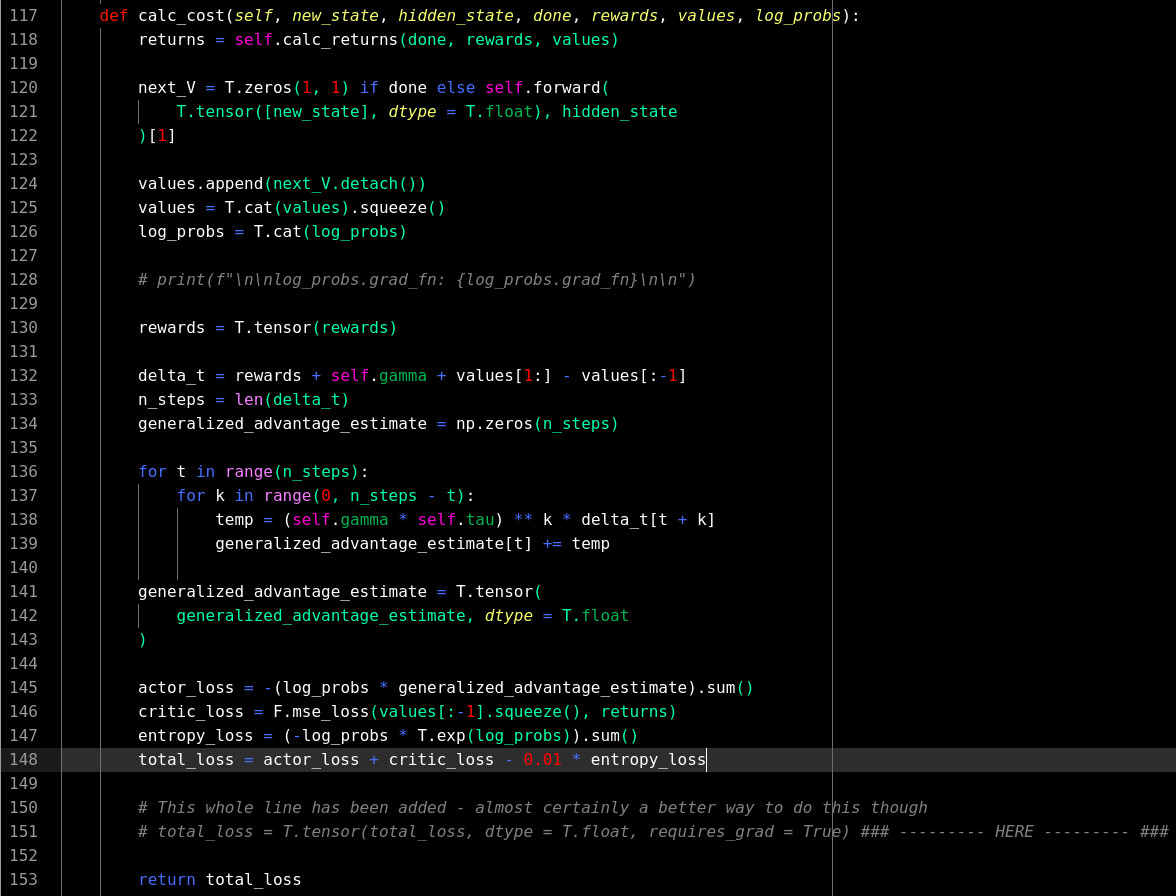
The actual error seems to consist somewhere in the backpropagation of the multi threaded loss function. The following is the function that is to be “multiplexed” - if you will. See the backprop error at the “HERE” comment:
def worker(name, input_shape, n_actions, global_agent, optimizer, env_id,
n_threads, global_idx):
T_max = 20
local_agent = ActorCriticNetwork(input_shape, n_actions)
memory = Memory()
# input shape has # channels first but the frame buffer must have # channels last
# swap the channels:
frame_buffer = [input_shape[1], input_shape[2], 1]
env = make_environment(env_id, shape = frame_buffer)
episode, max_eps, t_steps, scores = 0, 1000, 0, []
while episode < max_eps:
obs = env.reset()
score, done, ep_steps = 0, False, 0
hidden_state = T.zeros(1, 256)
while not done:
obs = T.tensor([obs], dtype = T.float)# obs = T.tensor(np.array(obs), dtype = T.float) # CURRENT
action, value, log_prob, hidden_state = local_agent(obs, hidden_state)
next_obs, reward, done, info = env.step(action)
memory.store_transition(reward, value, log_prob)
score += reward
ep_steps += 1
t_steps += 1
obs = next_obs
if ep_steps % T_max == 0 or done:
rewards, values, log_probs = memory.sample_memory()
loss = local_agent.calc_cost(
obs, hidden_state, done, rewards, values, log_probs
)
optimizer.zero_grad()
hidden_state = hidden_state.detach_()
# hidden_state = hidden_state.detach() # CURRENT
loss.backward() ### ------------------------ HERE ------------------------ ###
# loss.sum().backward() # CURRENT
T.nn.utils.clip_grad_norm_(local_agent.parameters(), 40)
for local_param, global_param in zip(
local_agent.parameters(),
global_agent.parameters()):
global_param._grad = local_param.grad
optimizer.step()
local_agent.load_state_dict(global_agent.state_dict())
memory.clear_memory()
episode += 1
with global_idx.get_lock():
global_idx.value += 1
if name == '1':
scores.append(score)
avg_score = np.mean(scores[-100:])
print(f'A3C episode: {episode}, thread: {name} of {n_threads}, steps: {t_steps/1e6}, score: {score}, avg_score: {avg_score}')
if name == '1':
x = [z for z in range(episode)]
plot_learning_curve(x, scores, 'A3C_pong_final.png')
I’ve scoured around for a while and found nothing particularly helpful. I’m happy to elaborate and to provide additional material/context. Any assistance will be greatly appreciated.
Many thanks,
Merlin ![]()