Hi, I am a starter of Pytorch. I want to implement a multi-wavelet function as an activation function. However, I don’t know how to set a function in this module.
`class MultiWavelet(nn.Module):
def __init__(self,out_features):
super(MultiWavelet, self).__init__()
self.out_features = out_features
self.scale = nn.Parameter(torch.Tensor(1,self.out_features),requires_grad = True)
self.shift = nn.Parameter(torch.Tensor(1,self.out_features),requires_grad = True)
self.a = nn.Parameter(torch.Tensor(1,self.out_features),requires_grad = True)
self.b = nn.Parameter(torch.Tensor(1,self.out_features),requires_grad = True)
def func1(self,c):
self.c = c
out = self.c.detach().numpy().copy()
out[out>=0 & out <1] = -2 * torch.pow(out,3) + 3 * torch.pow(out,2)
out[out>=1 & out <=2] = torch.pow((2-out),2) * (2*out - 1)
out[out <0 & out>2] = 0
return out
def Wavelet2(self,c):
self.c = c
out = self.c.detach().numpy().copy()
out[out>=0 & out <1] = -torch.pow(out,2) * (3 * out - 3)
out[out>=1 & out <=2] = -torch.pow((2-out),2) * (3* out - 3)
out[out <0 & out>2] = 0
return out
def forward(self, x):
x_out = (x-self.shift)/self.scale
h1 = self.Wavelet1(x_out)
h2 = self.Wavelet(x_out)
h = a. * h1 + b. * h2
return h`
In this case, I get a runtime error.That is TypeError: pow() received an invalid combination of arguments - got (numpy.ndarray, int), but expected one of:
- (Tensor input, Tensor exponent, Tensor out)
- (Number self, Tensor exponent, Tensor out)
- (Tensor input, Number exponent, Tensor out)
Thank you all in advance.
Could you remove the numpy() call from self.c and rerun the code?
Generally, if you don’t need to use another lib, I would recommend to use PyTorch methods only.
This will make sure that Autograd is able to keep track of all operations and create the backward pass for you automatically.
If you need to use another lib such as numpy, you would need to implement the backward function manually.
That being said, the current error is thrown, since out is a numpy array and you are trying to apply torch.pow on it.
Thank you for your reply.
I tried to remove the numpy() call from self.c, and it worked in the function. But there are some other problems such as Tensor could not use the copy(). So I remove the copy(), too. But for the matrix data processing, just like
b = torch.randn(2,2)*1.5
a = b.detach()
a[(a>=0) & (a <1)] = -2 * torch.pow(a,3) + 3 * torch.pow(a,2)
It is a RuntimeError.
RuntimeError: shape mismatch: value tensor of shape [2, 2] cannot be broadcast to indexing result of shape [1]
Is there a better grammar in torch could solve this problem.
Thank you for your time.
The left-hand side will return a variable number of elements (it could be empty, contain some elements, or all), while the right-hand side is a tensor in the shape [2, 2], which won’t work.
Could you explain, what you are trying to achieve?
Dear Ptrblck,
I am so sorry for I did not explain well.
I want to try this function through Pytorch.

So in a matrix, I want to classify numbers of different size ranges.
In this case, if I still don’t explain well, could you let me know? I will try again.
Thank you for your time.
For example, in this a matrix, a[(a>=0)& (a<1)] , I could get a tensor tensor([0.5340]). So I want this number could transform into -2 * torch.pow(tensor([0.5340]),3) + 3 * torch.pow(tensor([0.5340]),2) at the same place of this matrix.
Thanks for the clarification.
In that case, this might work:
b = torch.randn(2,2)*1.5
a = b.detach()
idx = (a>=0) & (a <1)
if idx.any():
a[idx] = -2 * torch.pow(a[idx],3) + 3 * torch.pow(a[idx],2)
Dear Ptrblck,
Thanks for your reply.
I try to use this code and get the right result. Is it the right grammar in Pytroch?

Thanks for your time.
Dear ptrblck,
I have another problem with this function. Do you think the activation function I built could be auto-grad?
class MultiWavelet(nn.Module):
def __init__(self,out_features):
super(MultiWavelet, self).__init__()
self.out_features = out_features
self.scale = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
self.shift = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
self.a = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
self.b = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
def Wavelet1(self,c):
self.c = c
out = self.c.detach()
out[(out>=0) & (out <1)] = -2 * torch.pow(out[(out>=0) & (out <1)],3) + 3 * torch.pow(out[(out>=0) & (out <1)],2)
out[(out>=1) & (out <=2)] = torch.pow((2-out[(out>=1) & (out <=2)]),2) * (2*out[(out>=1) & (out <=2)] - 1)
out[(out <0) | (out>2)] = 0
return out
def Wavelet2(self,c):
self.c = c
out = self.c.detach()
out[(out>=0) & (out <1)] = -torch.pow(out[(out>=0) & (out <1)],2) * (3 * out[(out>=0) & (out <1)] - 3)
out[(out>=1) & (out <=2)] = -torch.pow((2 - out[(out>=1) & (out <=2)]),2) * (3* out[(out>=1) & (out <=2)] - 3)
out[(out<0) | (out>2)] = 0
return out
def forward(self, x):
x_out = (x-self.shift)/self.scale
h1 = self.Wavelet1(x_out)
h2 = self.Wavelet2(x_out)
h = self.a * h1 + self.b * h2
return h
I need to compute these parameters, such as scale, shift, a, b, etc.
Look forward to hearing from you.
Best regards.
Since you are detaching c, the computation graph will be broken at this point, which means that self.shift and self.scale shouldn’t get any gradients.
Could you try to use .clone() instead or why are you detaching c at all? 
Thanks for your patience. It is my careless that I don’t understand .detach() well.
And if I set the parameters like this,
self.scale = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
self.shift = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
self.a = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
self.b = nn.Parameter(torch.randn(1,self.out_features),requires_grad = True)
I get the result like this.
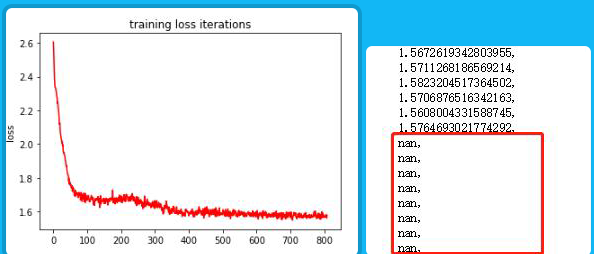
My loss functions set like this.
loss_func1 = nn.MSELoss()
loss_func2 = nn.CrossEntropyLoss()
loss1 = loss_func1(decoded, b_y.float()) # mean square error
loss2 = loss_func2(out, labels)
loss = loss1 + loss2
What are the possible reasons for this phenomenon? Gradient vanishing?
Thank you for your time.
Could you run your code with torch.autograd.set_detect_anomaly(True) and narrow down the operation, which creates the NaN values?
Also, could you check the input data for invalid values?