Hello Altruists,
I am working on a multiclass classification with image data. The training set has 9015 images of 7 different classes.
Target labeling looks like 0,1,0,0,0,0,0
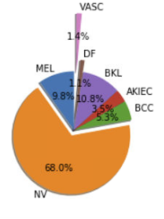
But the dataset is very much skewed to one class having 68% images and lowest amount is 1.1% belongs to another class. Please take a look at the figure below:
So my first question is: how can I augment/stratify the dataset with all classes having nearly same percentage of samples?
Moreover, for this multiclass classification how do I format the labels? For example, in MNIST the labels are 0 to 9 for different digit images.
So my first question is: how can I augment/stratify the dataset with all classes having nearly same percentage of samples?
The typical thing to do is keep a list-of-lists, say, self.data that contains for each class or stratum (first index) a list of examples. Then in your dataset’s __getitem__(self, idx) you use cls_no = idx % len(self.data) to get the class and then x = self.data[cls_no][(idx // len(self.data)) % len(self.data[cls_no])] to as the sample to return. You will then have to choose the epoch length appropriately, e.g. len(self.data) * max([len(x) for x in self.data]) or so. If you have a length shorter than that you might want to shuffle the order of the examples in self.data[…] after each epoch.
What if I oversample all the minor classes to the largest class (#6120) in a list and then do the sorting/dataset from the list?
This way there will be 7*6120 = 42840 image training.
Does that anyhow compromise the training process?
One thing I understand I need to input all the images from all classes in the network.
After creating the list of lists as you mentioned, the image name list has following class and samples:
The training epoch will be ~5x longer, but that’s just loosing some time.
If you want, it skews the meaning of the training loss (which you could collect per class and then apply a weighted mean if you want to compare to the validation loss). Other than that it seems to me that rebalancing the training data is a relatively straightforward path to dealing with imbalanced classification. For me, it seams to be more reliable to get good results than loss weighting.
According to this class imbalance paper the authors mention that oversampling the minority class is the best solution. So I was thinking about giving it a try.
Since I have a balanced class now, do you think that training loss will be skewed, as the network will see the same minor class images more frequently than majority class ones?