Hi,
I’m trying to do multi-class semantic segmentation on modified Cityscapes dataset. Masks have been modified so that color(shade of gray) matches id of the class. Since i’m new to pytorch i don’t know if setup of my project is any good.
This is my dataloader (Note: i’m resizing images to 100x100 just so i can test training before running it on dedicated machines)
import torch
from torch.utils.data.dataset import Dataset # For custom data-sets
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision.transforms.functional as TF
from PIL import Image
import glob
import random
import numpy as np
import matplotlib.pyplot as plt
train_image_path = glob.glob("/home/filip/diplomski-code/data/rvc_uint8/images/train/cityscapes-34/*.png")
train_mask_path = glob.glob("/home/filip/diplomski-code/data/rvc_uint8/annotations/train/cityscapes-34/*.png")
val_image_path = glob.glob("/home/filip/diplomski-code/data/rvc_uint8/images/val/cityscapes-34/*.png")
val_mask_path = glob.glob("/home/filip/diplomski-code/data/rvc_uint8/annotations/val/cityscapes-34/*.png")
class MyDataset(Dataset):
def __init__(self, image_path, mask_path,train=True):
self.image_path = image_path
self.mask_path = mask_path
self.transformT = transforms.ToTensor()
def mask_to_class(self, mask):
for k in self.mapping:
mask[mask==k] = self.mapping[k]
return mask
def transform(self, image, mask):
resize = transforms.Resize(size=(100,100), interpolation=Image.NEAREST) #Resize
image = resize(image)
mask = resize(mask)
#Random crop
i, j, h, w = transforms.RandomCrop.get_params(image, output_size=(90,90))
image = TF.crop(image,i,j,h,w)
mask = TF.crop(mask, i ,j, h, w)
#Random vertical flip
if random.random() > 0.5:
image = TF.vflip(image)
mask = TF.vflip(mask)
return image, mask
def __getitem__(self, index):
image = Image.open(self.image_path[index])
mask = Image.open(self.mask_path[index])
image, mask = self.transform(image, mask)
image = self.transformT(image)
mask = torch.from_numpy(np.array(mask, dtype=np.uint8))
#mask = self.mask_to_class(mask)
mask = mask.long()
return image, mask
def __len__(self):
return len(self.image_path)
train_dataset = MyDataset(train_image_path, train_mask_path, train=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True)
val_dataset = MyDataset(val_image_path, val_mask_path, train=True)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=16, shuffle=False)
batch_x, batch_y = next(iter(val_dataloader))
print('y shape ', batch_y.shape)
print('x shape ', batch_x.shape)
#print('unique values of x rgb ', torch.unique(batch_x[0]))
print('unique values y ', torch.unique(batch_y))
print(sorted(np.unique(np.array(batch_y))))
x=torch.unique(batch_y)
print(x.shape)
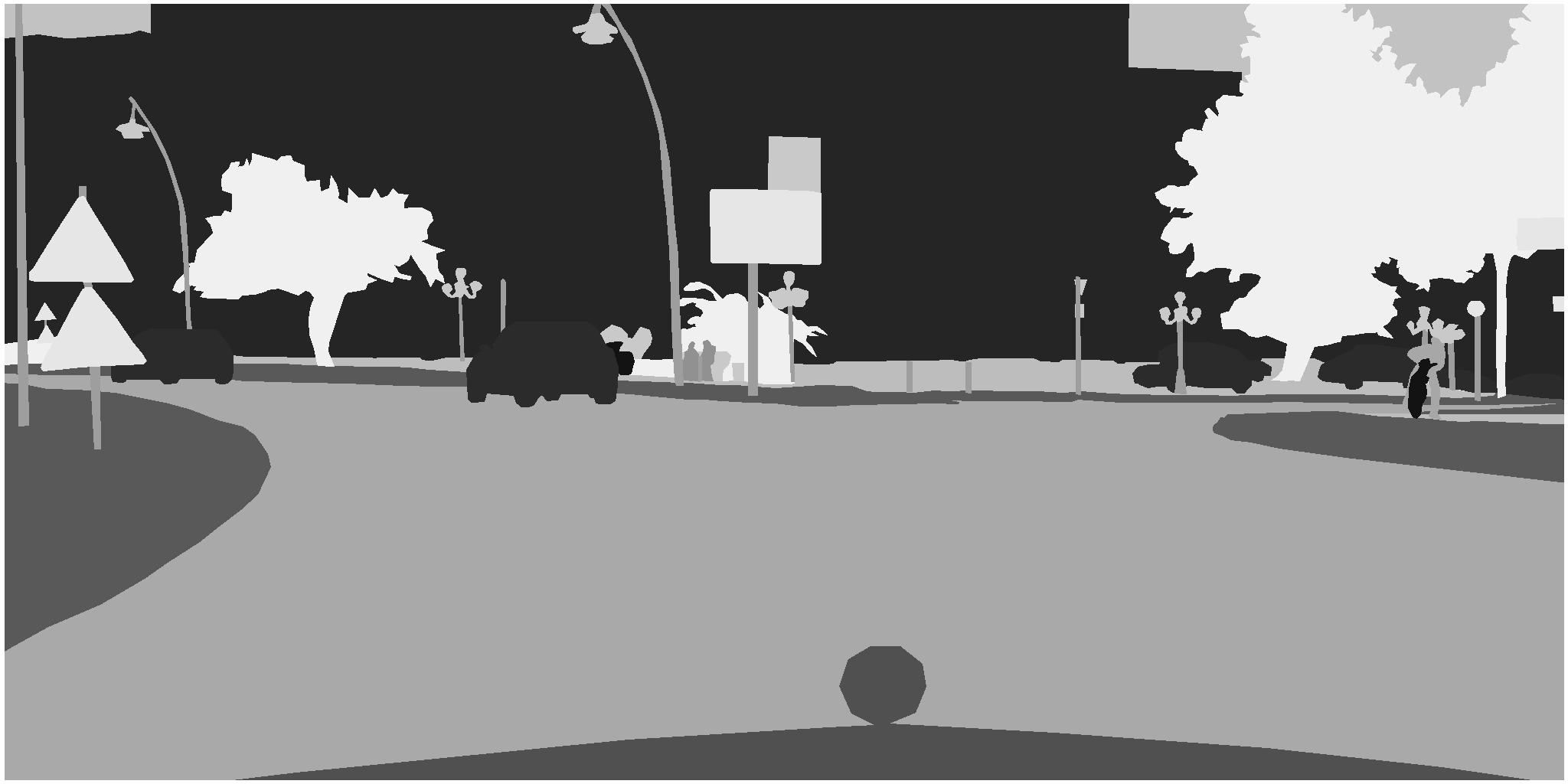
This is the example of image and of the mask:

This is how i defined pixel accuracy and mIoU, which i used in training script:
import torch
import numpy as np
import torch.nn.functional as F
def pixel_accuracy(output, mask):
with torch.no_grad():
output = torch.argmax(F.softmax(output, dim=1), dim=1)
correct = torch.eq(output, mask).int()
accuracy = float(correct.sum()) / float(correct.numel())
return accuracy
def mIoU(pred_mask, mask, smooth=1e-10, n_classes=256):
with torch.no_grad():
pred_mask = F.softmax(pred_mask, dim=1)
pred_mask = torch.argmax(pred_mask, dim=1)
pred_mask = pred_mask.contiguous().view(-1)
mask = mask.contiguous().view(-1)
iou_per_class = []
for clas in range(0, n_classes): #loop per pixel class
true_class = pred_mask == clas
true_label = mask == clas
if true_label.long().sum().item() == 0: #no exist label in this loop
iou_per_class.append(np.nan)
else:
intersect = torch.logical_and(true_class, true_label).sum().float().item()
union = torch.logical_or(true_class, true_label).sum().float().item()
iou = (intersect + smooth) / (union +smooth)
iou_per_class.append(iou)
return np.nanmean(iou_per_class)
And this is a script i use for training(Note: i’m preparing it for later use with different args because I later want to train same model on multiple datasets - robust vision challenge)
import torch
import argparse
from torch import nn
import numpy as np
from model.model import custom_DeepLabv3
from model.metrics import mIoU, pixel_accuracy
from dataloader.dataloader2 import train_dataset, val_dataset
import matplotlib.pyplot as plt
def get_argparser():
parser = argparse.ArgumentParser()
#Dataset Options
parser.add_argument("--dataset",type=str,default='cityscapes',
choices=['cityscapes','kitti','mapillary','viper','wilddash'],help="Name of dataset")
parser.add_argument("--epochs", type=int, default = 100,
help = "number of epochs to train for(default = 100)")
parser.add_argument("--learning_rate", type=float, default=1e-3,
help="set the learning rate(default = 1e-3")
#Ako cu ga koristiti
parser.add_argument("--weight_decay", type=float, default=1e-4,
help='weight decay (default: 1e-4)')
parser.add_argument("--batch_size",type=int,default=16,help="set the batch size(default=16)")
#Dodati jos loss funkcija ako ce se eksperimentirati
parser.add_argument("--loss_function",type=str, default="CrossEntropyLoss",choices=["CrossEntropyLoss"],help="define loss type")
return parser
opts = get_argparser().parse_args()
learning_rate = opts.learning_rate
batch_size = opts.batch_size
epochs = opts.epochs
model=custom_DeepLabv3(256)
model=model.to('cuda')
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.01)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
train_losses = []
val_losses = []
val_iou = []; val_acc = []
train_iou = []; train_acc = []
min_loss = np.inf
decrease = 1 ; not_improve=0
for epoch in range(epochs):
running_loss = 0
iou_score=0
accuracy = 0
print(f"Epoch {epoch+1}\n-------------------------------")
#training
for i, data in enumerate(train_dataloader):
model.train()
# Compute prediction and loss
x, y = data
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
pred = model(x)
#print(pred['out'].shape)
loss = loss_fn(pred['out'],y)
#eval metrics
iou_score += mIoU(pred['out'], y)
accuracy +=pixel_accuracy(pred['out'], y)
# Backpropagation
loss.backward()
optimizer.step()
optimizer.zero_grad()
#loss
running_loss += loss.item()
train_losses.append(running_loss/len(train_dataloader))
#validation
val_loss = 0
val_accuracy = 0
val_iou_score = 0
for i, data in enumerate(val_dataloader):
model.eval()
with torch.no_grad():
x, y = data
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
#print(x.shape)
pred = model(x)
#print(pred['out'].shape)
#eval metrics
val_iou_score += mIoU(pred['out'], y)
val_accuracy += pixel_accuracy(pred['out'], y)
loss = loss_fn(pred['out'], y)
val_loss += loss.item()
val_losses.append(val_loss/len(val_dataloader))
#metrics report
val_iou.append(val_iou_score/len(val_dataloader))
train_iou.append(iou_score/len(train_dataloader))
train_acc.append(accuracy/len(train_dataloader))
val_acc.append(val_accuracy/ len(val_dataloader))
print("Epoch:{}/{}..".format(epoch+1, epochs),
"Train Loss: {:.3f}..".format(running_loss/len(train_dataloader)),
"Val Loss: {:.3f}..".format(val_loss/len(val_dataloader)),
"Train mIoU:{:.3f}..".format(iou_score/len(train_dataloader)),
"Val mIoU: {:.3f}..".format(val_iou_score/len(val_dataloader)),
"Train Acc:{:.3f}..".format(accuracy/len(train_dataloader)),
"Val Acc:{:.3f}..".format(val_accuracy/len(val_dataloader)))
#saving model with min loss
if min_loss > (val_loss/len(val_dataloader)):
print('Loss Decreasing.. {:.3f} >> {:.3f} '.format(min_loss, (val_loss/len(val_dataloader))))
min_loss = (val_loss/len(val_dataloader))
decrease += 1
if decrease % 5 == 0:
print('saving model...')
torch.save(model, 'model_folder/DeepLabV3_mIoU-{:.3f}.pth'.format(val_iou_score/len(val_dataloader)))
#plot history
history = {'train_loss' : train_losses, 'val_loss': val_losses,
'train_miou' :train_iou, 'val_miou':val_iou,
'train_acc' :train_acc, 'val_acc':val_acc}
def plot_loss(history):
plt.plot(history['val_loss'], label='val', marker='*')
plt.plot( history['train_loss'], label='train', marker='*')
plt.title('Loss per epoch'); plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.savefig('plt_loss_score_adamW.png')
plt.show()
def plot_score(history):
plt.plot(history['train_miou'], label='train_mIoU', marker='*')
plt.plot(history['val_miou'], label='val_mIoU', marker='*')
plt.title('Score per epoch'); plt.ylabel('mean IoU')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.savefig('plt_miou_score_adamW.png')
plt.show()
def plot_acc(history):
plt.plot(history['train_acc'], label='train_accuracy', marker='*')
plt.plot(history['val_acc'], label='val_accuracy', marker='*')
plt.title('Accuracy per epoch'); plt.ylabel('Accuracy')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.savefig('plt_acc_score_adamW.png')
plt.show()
plot_loss(history)
plot_score(history)
plot_acc(history)
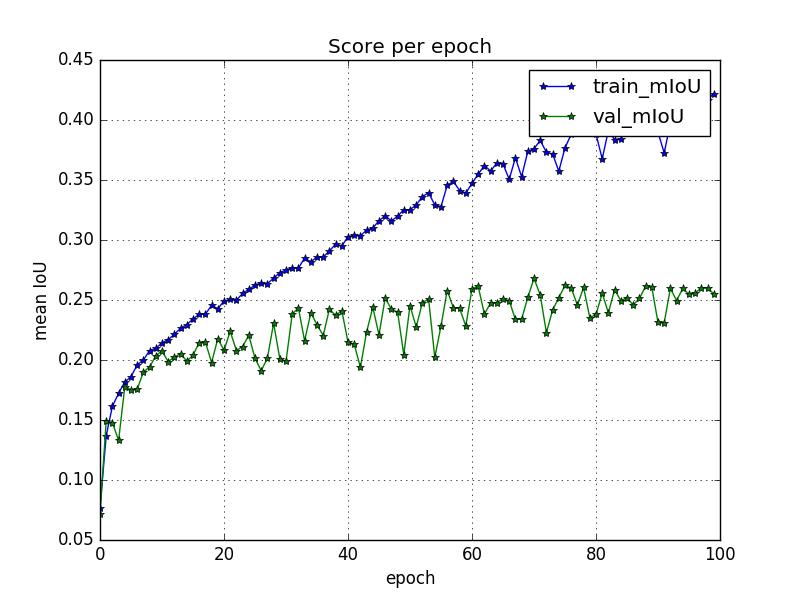
My training seems to run and I get mIoU scores as shown on the picture belowe , which does indicate to overfitting but i just want to make sure everything is setup properly before optimizing and experimenting. No point in experimenting if something is fundamentally wrong.
Thanks for reading ! All comments are welcome!