Hi all,
I encounter a strange problem:
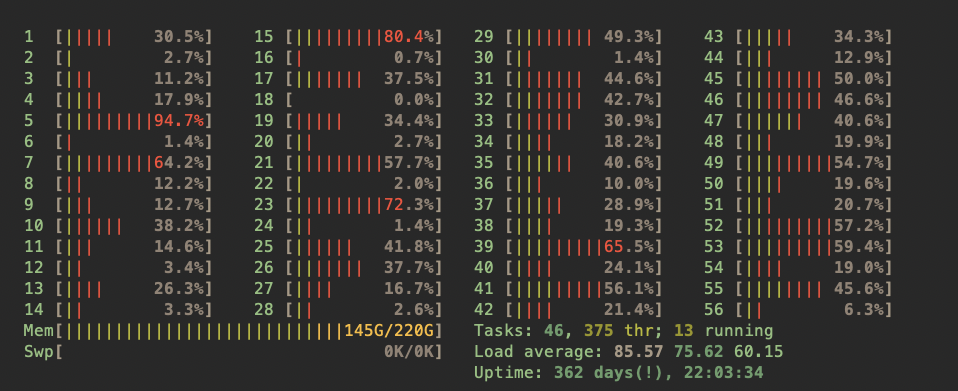
Previously, I define my collat_batch function to collect preprocessed data in numpy format, and set pin_memory = Ture; In the training loop, I iter a batch, then move the batch from numpy to gpu device; This way couldn’t make full use of cpu so that even GPU is waiting for data, cpu isn’t running fully.
Then I change the above process, I define a collate_batch_torch function to collect preprocessed data in numpy format then convert it to torch.tensor, set pin_memory = True; In the training loop, I iter a batch, then move the batch from torch.tensor to device; This can make cpu running fully, but the step time is much slower; so it seems that this modification make cpu the bottelneck.
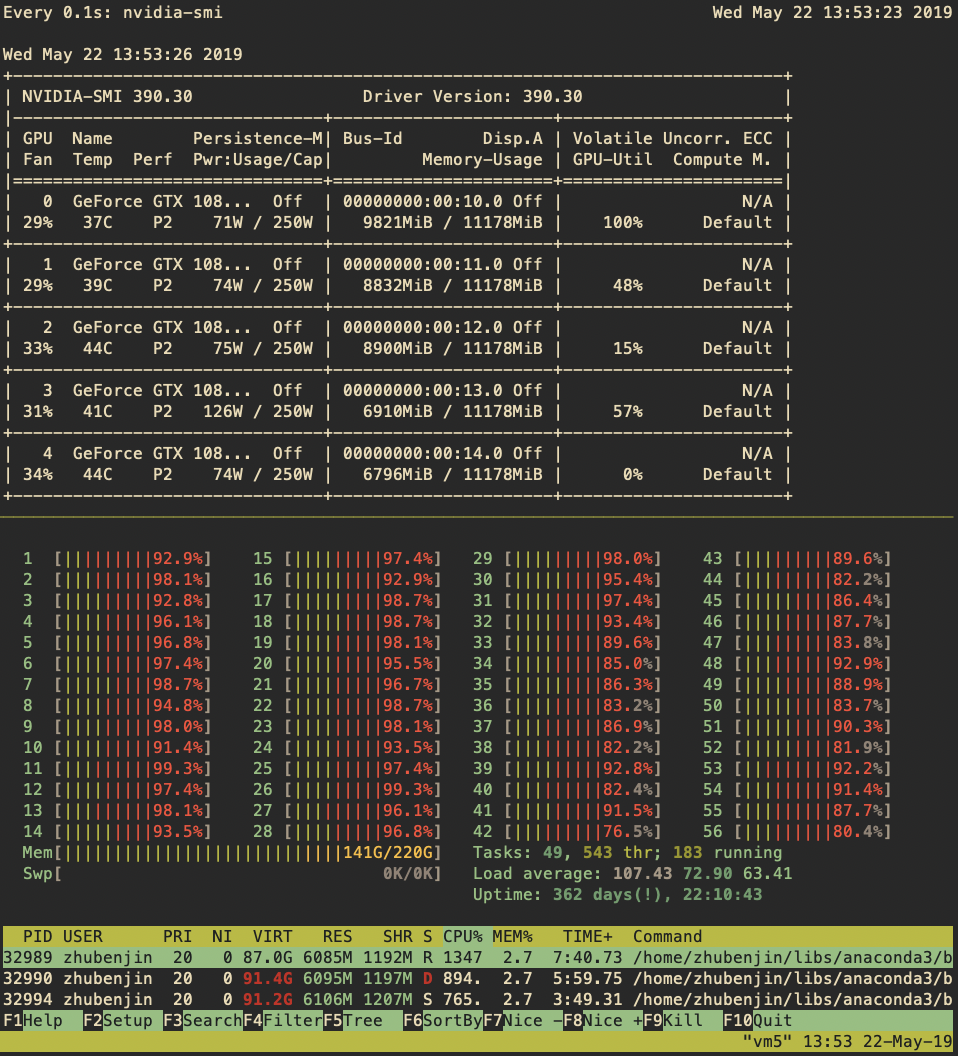
When I test it using one gpu or two gpus, the accelerate rate is linear. for example, using one gpu, time cost per iteration is 1s, two gpu is also 1s, but when I use 8 gpus, time could be 8s.
What’s wrong?