I have 3 GPUs (80GB each) on my virtual machine, however for some reason pytorch only uses one of the GPUs.
Please see minimal reproduction of my code
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0, 1, 2"
from torch import nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Network(**kwargs)
model = nn.DataParallel(model)
model.to(device)
trainloader = DataLoader(ImagesDataset('/ResizedImages', image_size), batch_size=batch_size,shuffle=True, num_workers=int(num_workers))
for i in range(EPOCHS):
for img in trainloader:
img_ = img.to(device)
loss = model(img_)
opt.zero_grad()
loss.backward()
opt.step()
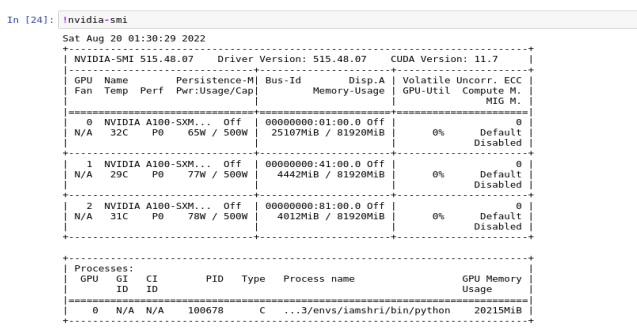
When I run nvidia-smi after training, I get the output screenshot- meaning my training only uses 1 GPU. Is this due to the size of my network being minimal and thus training does not require that large memory (80GB x 3) or I am getting something wrong?
Many thanks!