mha = nn.MultiheadAttention(512, 4, bias=False)
[p.shape for p in mha.parameters()]
outputs
[torch.Size([1536, 512]), torch.Size([512, 512]), torch.Size([512])]
So I see indices 1 and 2 as comprising an “extra” linear layer.
Following Attention Is All You Need, I wasn’t aware of the extra linear layer as part of multi-head attention.
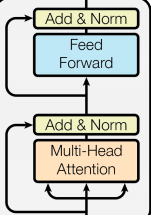
Although they do have the blue Feed Forward box, I see that as a separate component.
So what’s going on in the PyTorch implementation? Is there an easy way to drop it?