I tried to set k_dim differently than embed_dim, but I got an error stating they should be the same!? I am wondering how one needs to set the values in the module, what’s the point if you can’t set them differently?
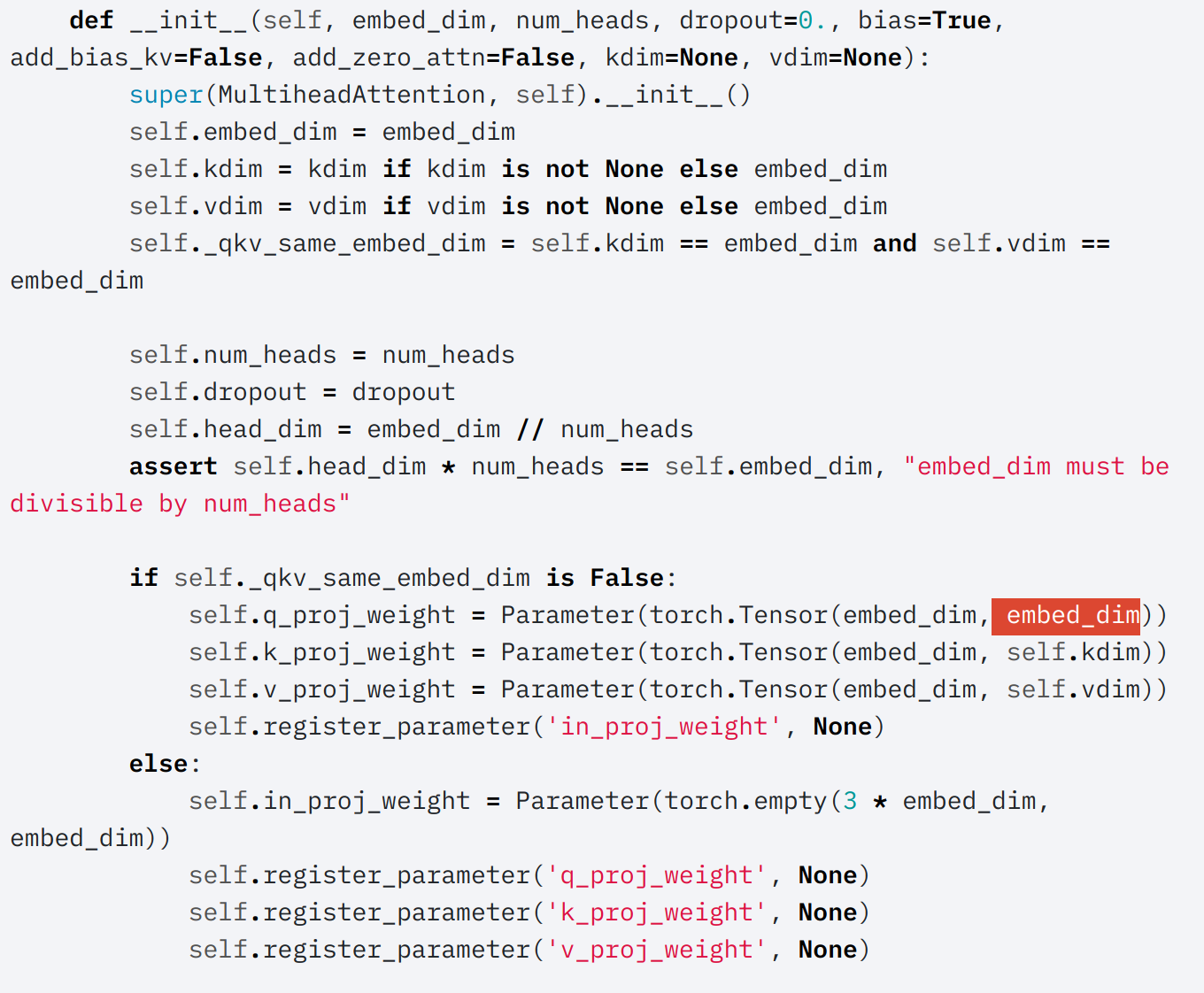
I looked at the source code, now I am wondering if I misunderstand the implementation or if there is an error in the implementation? The dimension for the q embedding should be the same as kdim in my opinion (in red), as q and v are used for calculating the correlations. Why is it set to embed_dim?
Thanks for your answer. I think there is a misunderstanding from my side: I expected the module (nn.MultiheadAttention) to embed q, k, v values inside the module according to kdim, vdim and ideally qdim=kdim. The way the module is implemented, unfortunately it is not possible to use different embedding dimensions for the attention operation.
In my opinion it would be much more useful to be able to perform attention in individual dimensions for kdim and vdim. Is there a function or module that only performs attention without internal embedding stage?
I can’t believe this is still not fixed after 3 years. In the posted screenshot, obviously the highlighted embed_dim should be replaced with self.kdim (kdim and qdim must be equal to be able to compute scalar products). I guess everyone must be rolling their own attention code who needs kdim different from embed dim. I just found this amazing project, look for “Transformer’s attention needs more attention” on this page: Writing better code with pytorch+einops