Hi,
I have a multilabel classification problem, which I am trying to solve with CNNs in Pytorch. I have 80,000 training examples and 7900 classes; every example can belong to multiple classes at the same time, mean number of classes per example is 130. Here is the plot that shows numbers of samples per each class:
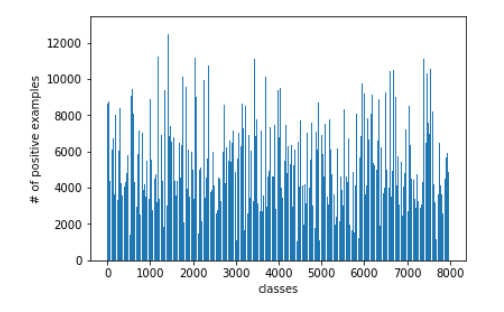
As you can see the data is very imbalanced. For some classes, I have only ~900 examples, which is around 1%. For “overrepresented” classes I have ~12000 examples (15%). When I train the model I use BCEWithLogitsLoss with a positive weights parameter. I calculate the weights the same way as described in the documentation: the number of negative examples divided by the number of positives.
As a result, my model overestimates almost every class… Mor minor and major classes I get almost twice as many predictions as true labels. And my AUPRC is just 0.18. Even though it’s much better than no weighting at all, since in this case the model predicts everything as zero.
So my question is, how do I improve the performance? Is there anything else I can do? I tried different batch sampling techniques (to oversample minority class), but they don’t seem to work.
I’d recommend trying out using softmax with cross entropy with each target class set to 1/num_target_labels. That has usually worked better for me than binary cross entropy and sigmoid outputs.
There are a few papers from facebook that also mention doing that ([1805.00932] Exploring the Limits of Weakly Supervised Pretraining)

1 Like
Try to augment the under-represented class and undersample the dominant class to some extent. I think augmentation + BCEWithLogitsLoss(and without weights assigned) should improve the accuracy by a significant amount.
hi @michalwols
incase of softmax with CE with ground truth set to 1/num_target_labels, what will be the threshold above which you choose the class during inference? won’t it vary depending on num_target_labels for every example?
Thank you! But how do I do augmentation in multilabel case?
Can you give me an overall picture of the problem that you’re trying to solve? You have mentioned that every example has an average of 130 class labels.
- Do you think detection could help in such a case?(but annotating 80K samples can be expensive)
- Can you use existing detectors to run on the train set, extract individual class objects and add them(along with augmentation) to your train set? This may help in tackling class imbalance.