Let me explain: I want to fine-tune the segment-anything-model, which consists of a heavyweight image encoder network, a small encoder for the prompts (points or bboxes) and a lightweight mask decoder.
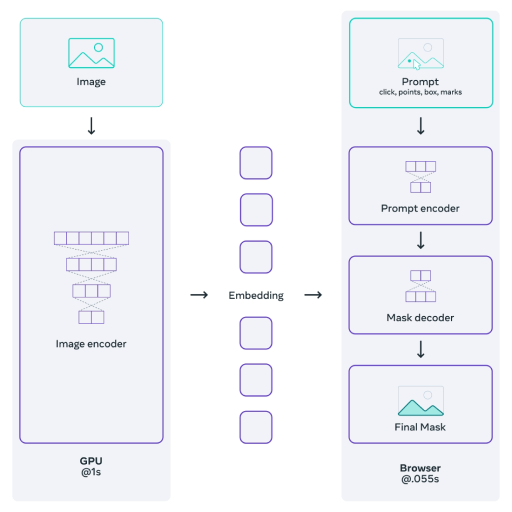
A typical training image will have ~50 bboxes. So for a single image, we do 1 forward pass through the image encoder. Assuming we prompt the model with a batch of 10 bounding boxes, we will thus do 50/10=5 forward passes through the other downstream smaller models (mask decoder). This is a problem because after the first backward pass, the gradients of the big image encoder are flushed.
What would be the canonical way to deal with this? Should I put the intermediate output of the image encoder in some sort of buffer?