Hi there,
I am training on two GPUs and I noticed that the first GPU uses significantly more memory. How can that be? I moved the model to both GPUs with DataParallel.
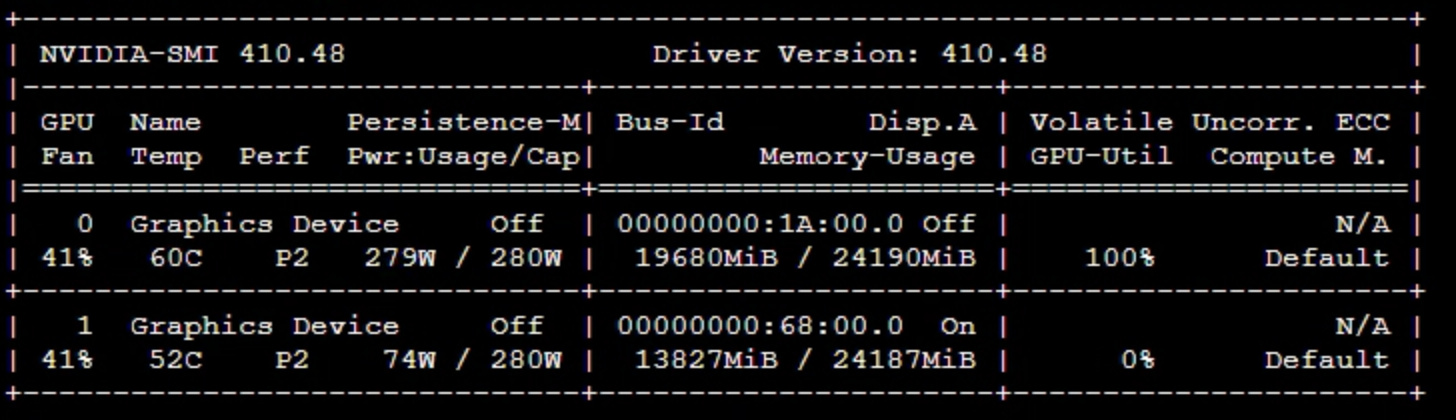
Thanks for your help.
Hi there,
I am training on two GPUs and I noticed that the first GPU uses significantly more memory. How can that be? I moved the model to both GPUs with DataParallel.
Thanks for your help.
It’s about the optimizer you are using (I guess) and probably because you may be preallocating the whole batch in gpu 0.
DataParallel has a kind of “main gpu”. Even if the whole model is copied in each gpu, thing such us optimizer parameters remain in the main one. Let me know if using plain SGD you still observing such a big difference.
SGD consumes the same amount.
Hi,
are you loading a pretrained model? Loading those weights may occupy some memory if you load them directly on gpu.
Be aware output for both gpus are gathered back in the main one.
Hi Juan,
that might be the case yes (it’s a “small” pretrained autoencoder model I am loading next to the one I want to train). Are there any best practices/examples how to evenly use GPU memory when using more than 1 GPU?
I also had situations where output was on one GPU but target on the other one.
When building the model, is there any good example to avoid those kind of situations?
I might have the behavior explained in https://github.com/pytorch/pytorch/issues/8637
Is there any resource that explains bad and good model design?
There is an issue in which if you load a state_dict, it maps to gpu. Once loaded it’s never fred.
This means that when you do:
model.load_state_dict(torch.load(path_to_weights)) those weights are using gpu memory never fred.
Try this way.
state_dict = torch.load(directory, map_location=lambda storage, loc: storage) model.load_state_dict(state_dict)
it will force state dict to be loaded on RAM instead of gpu directly.
Regarding the issue you mentioned, it’s not very typical.
In general, dataparallel duplicates everything in each gpu, thus, there shouldn’t be higher memory comsuption.
Extra compsumtion usually comes from one of these 3 issues:
input/output tensor are gathered on main gpu (which should denote an slightly higher mem comp)
optimizer memory requirments
and state_dict issues.