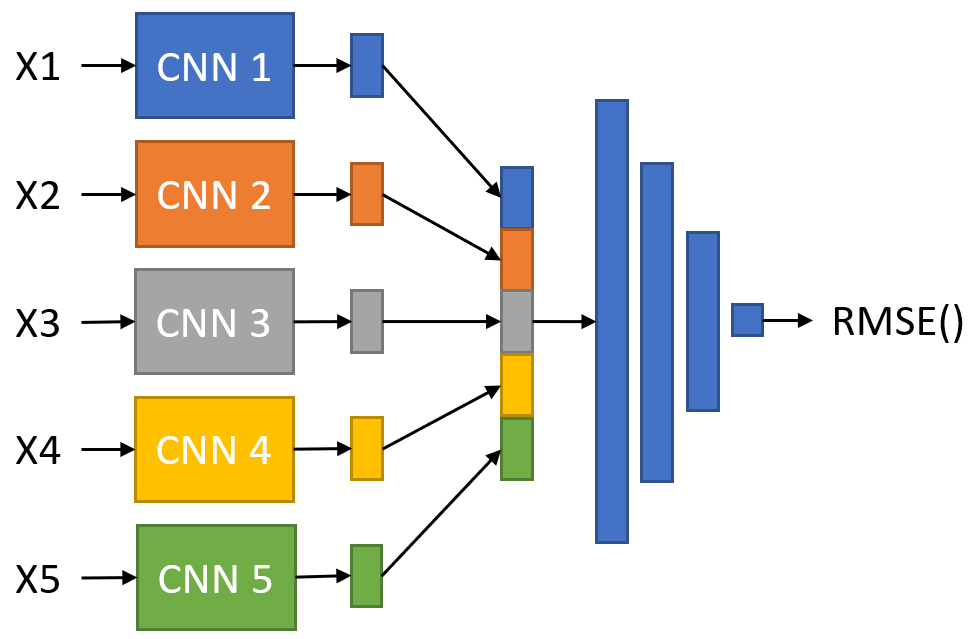
I would like to create a pipeline that 1) accepts 5 different inputs 2) learns a distinct CNN for each input 3) concatenates the outputs of each CNN together 4) feeds that output to a series for fully connected layers 5) calculates the loss and back propagates the gradients to all the layers in the entire pipeline (see figure below). I am unsure how to correctly do this. Would I do something like the following? The 5 CNNs cannot share weights. Thank you!
class MyNet():
def __init__():
self.cnn1 = nn.Sequential(nn.Conv2d(....
self.cnn2 = nn.Sequential(nn.Conv2d(....
self.cnn3 = nn.Sequential(nn.Conv2d(....
self.cnn4 = nn.Sequential(nn.Conv2d(....
self.cnn5 = nn.Sequential(nn.Conv2d(....
self.fc = nn.Sequential(nn.linear(...
def forward(self, x1, x2, x3, x4, x5):
x1 = self.cnn1(x1)
x2 = self.cnn1(x2)
x3 = self.cnn1(x3)
x4 = self.cnn1(x4)
x5 = self.cnn1(x5)
x = torch.cat([x1, x2, x3, x4, x5])
x = self.fc(x)
return x
Yes, that should work
Make sure to initialize the nn.Module base class.
I ended up coding the below, but after a few batches the loss goes to nan regardless of what learning rate I choose. Can anyone think of why this might be?
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.features = nn.Sequential(nn.Conv1d(...
self.avgpool = nn.AdaptiveAvgPool1d(...
self.classifier = nn.Sequential(nn.Linear(...
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
class FC(nn.Module):
def __init__(self):
super(FC, self).__init__()
self.regressor = nn.Sequential(nn.Linear(...
def forward(self, x):
x = self.regressor(x)
return x
class Pipeline(nn.Module):
def __init__(self, num_channels=5, device="cuda"):
super(Pipeline, self).__init__()
# Create a list of CNN models, one for each channel in the input
self.cnns = []
for i in range(num_channels):
model = CNN()
model = model.to(device)
self.cnns.append(model)
model = FC_Net()
model = model.to(device)
self.regressor = model
def forward(self, x):
# Process each channel in its own CNN
# Input is in batch x channels x length format
latents = []
for i in range(x.shape[1]):
latents.append(self.cnns[i](x[:,[i],:]))
# Concat the results and pass through a fully connected net
latents = torch.cat(latents, axis=1)
x = self.regressor(latents)
return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Pipeline(device=device)
model.to(device)
model.eval()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum, weight_decay=weight_decay)
criterion = nn.MSELoss()
for i, (X, y) in enumerate(training_data_loader):
optimizer.zero_grad()
X = X.to(device)
y = y.to(device)
yh = model(X)
# yh.shape = (64, 1) vs y.shape = (64,)
yh = yh.reshape(-1)
loss = criterion(y, yh)
loss.backward()
optimizer.step()