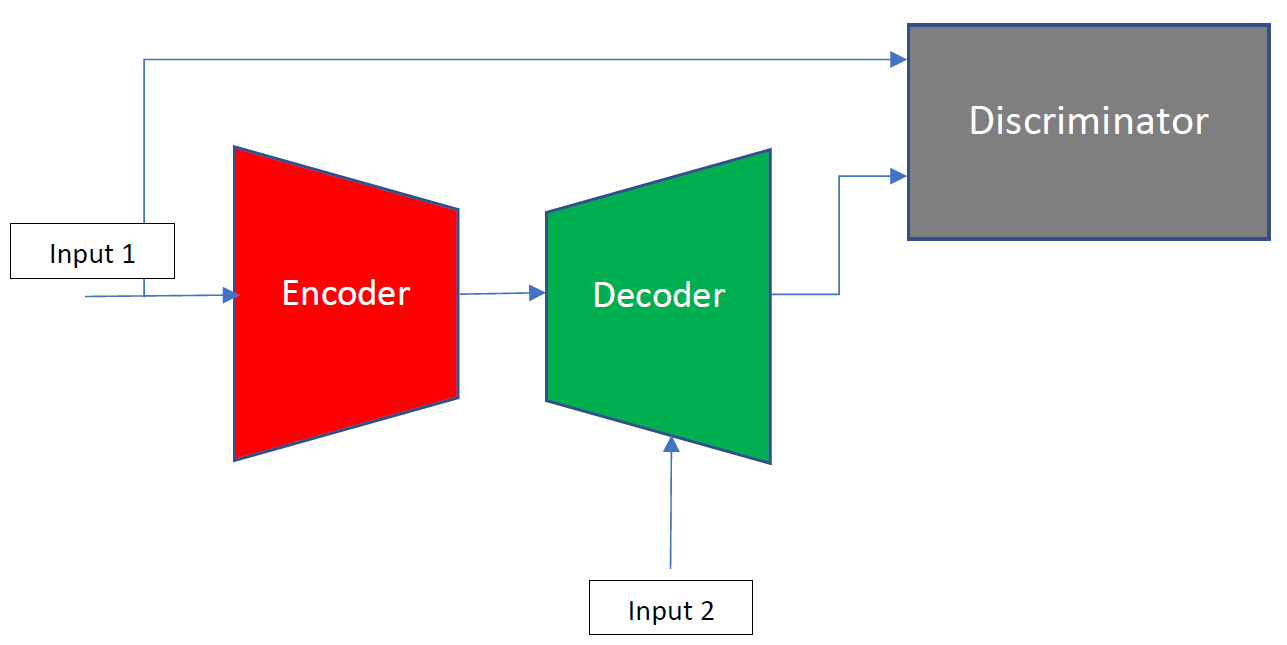
I am trying to train a model constructed of three different modules. An encoder, a decoder, and a discriminator. These three are connected as follows. Each of these three should minimize its own loss function which is different from the others.
I am getting the following error:
RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already been freed. Specify retain_graph=True when calling backward the first time.
When I use retain_graph=True (loss_ele.backward(retain_graph=True)), I get the following error:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [450, 45]] is at version 2; expected version 1 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later.
This is because the loss function releases the data after the backward pass. Because you are passing the outputs_dec into the discriminator after the loss has already been computed for the encoder the graphs combine. To stop this you can do
Thanks for the reply. I tried disc_fake = model_disc(outputs_dec.detach(), Disc_hiddens).view(-1) but I am still getting the same error:
File “…/Temp.py”, line 167, in …
loss_decoder.backward(retain_graph=True)
File “…/lib/python3.6/site-packages/torch/tensor.py”, line 221, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File “…/lib/python3.6/site-packages/torch/autograd/init.py”, line 132, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [450, 45]] is at version 2; expected version 1 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later.
Thanks for the reply. Yeah, I am using the retain_graph=True with the loss_decoder as well. Otherwise, I am getting the first error (Trying to backward through the graph a second time, but the saved intermediate results have already been freed. Specify retain_graph=True when calling backward the first time). With using retain_graph for these two I am getting the second one (one of the variables needed for gradient computation has been modified by an inplace operation)
This looks tricky to achieve with multiple optimizers.
I am not sure if this is the reason. But you are calling multiple optimizer.step()'s in between and the weights of the encoder, decoder are modified in-place due to that. What if you try the weight updates in reverse order (discriminator, then decoder, then encoder):
Yeah, you’re right. I want them to be connected to each other.
BTW, I tried what you mentioned and I am getting a similar error message:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [60000, 1]], which is output 0 of TBackward, is at version 2; expected version 1 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
Here I copy my discriminator class in case it is the reason for the issue:
class Discriminator(nn.Module):
def init(self, cfg):
super(Discriminator, self).init()
You can use del lossD instead of final lossD.backward() (to release computational graph). Can you try that?
Edit: Can you pack encoder and decoder into one optimizer (or) backward them together, if possible? The Encoder grad calculation is dependent on Decoder parameters as well. So, you can’t optimizer_decoder.step() before loss_ele.backward(). One solution is as follows:
calculate encoder loss, decoder loss, discriminator loss
# discriminator update
optimizer_disc.zero_grad()
lossD.backward(retain_graph=True)
optimizer_disc.step()
# encoder and decoder update
optimizer_encoder.zero_grad()
optimizer_decoder.zero_grad()
loss_generator = loss_encoder + loss_decoder
loss_generator.backward()
optimizer_decoder.step()
optimizer_encoder.step()
# to release the computation graph of the discriminator
del lossD