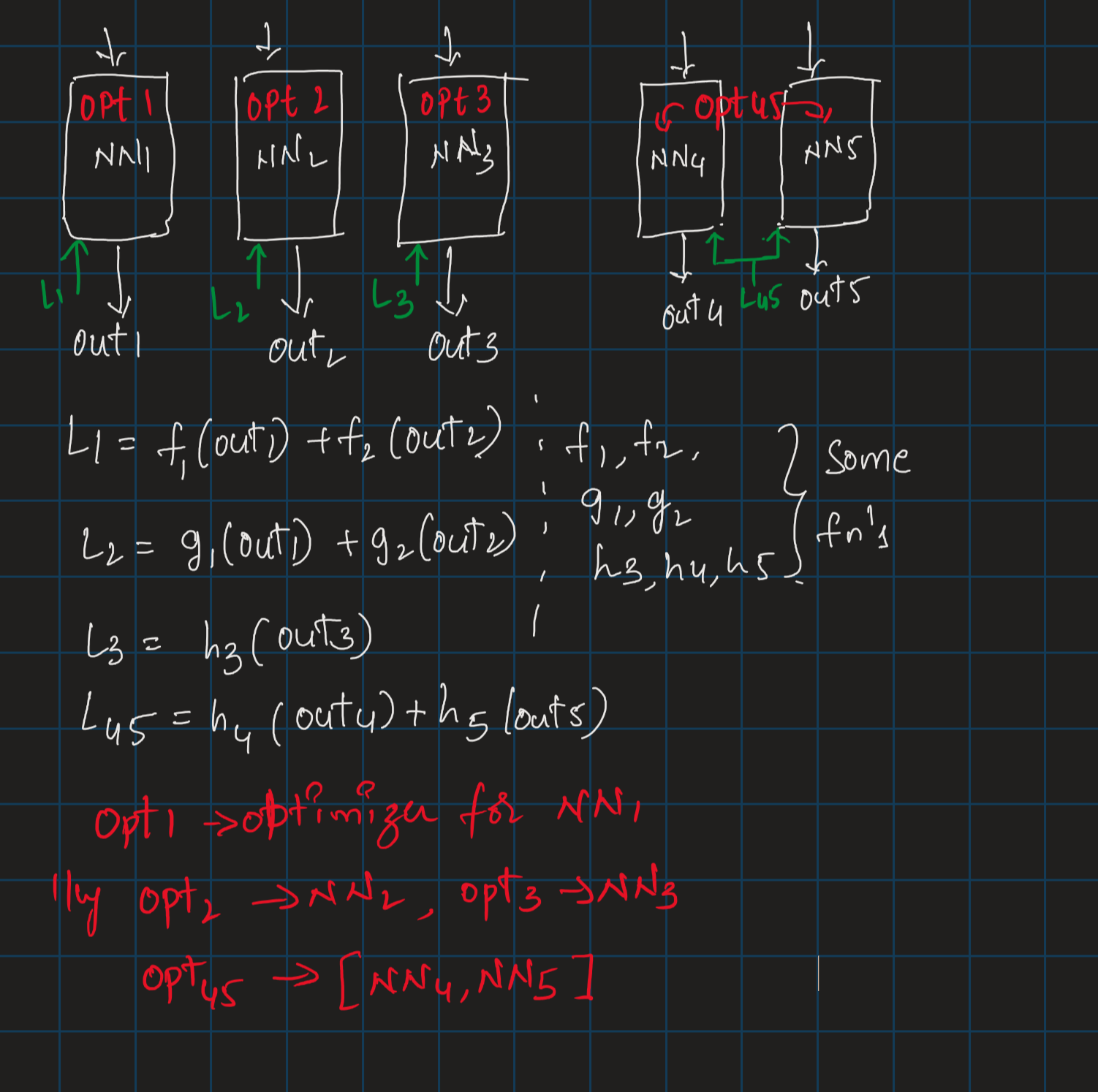Setup - Only for scenario explanation, any technical gaps please ignore :
Let’s say for a hypothetical robotic system where all the networks shown above are designed to handle different functionalities based on what it sees, i.e., Input for all the models is the same (camera) and outputs are :
Out1: Object tracking
Out2: Ego Path estimation and Collision probability
Out3: Face recognition
Out4: Object recognition
Out5: Object segmentation
Opt1, Opt2, Opt3 are optimizers defined for NN1, NN2, NN3.
and Opt45 common for [NN4,NN5]
The assumption is all the networks have to be trained together with losses defined as shown (Just to get a holistic understanding of backprop.)
Note: NN1 and NN2 are inter-dependent on Out1 and Out2, but they don’t explore the same loss function (L1 != L2).
How can we achieve the backward prop shown in figure (in green), what should be the sequence of loss.backward() and optimizer.step() calls for each loss and optimizer?
So when you call backwards on L1, it’ll traverse backwards and assign gradients to any parameters who are to blame for its loss. What I’m noticing is that L1 takes as input, the output of NN1 and NN2, therefore gradients will flow through both of them. But according to your diagram, do you not want L1 to flow through NN2? If this is the case, L1should not take out2 as input. What you can do is detach out2 from the computational graph and use it as a constant in your loss (as to not allow gradients to flow through it), but since your loss is a sum of the two, this won’t achieve anything.
So I would suggest removing out2 from L1 and out1 from L2 for similar reasons.
L3 looks completely fine to me.
L45 also looks fine to me. The order at which you call backwards won’t really matter since they’re not overlapping with each other. The key thing is that what parameters that affected your loss comes before the optimizer that is in charge of those parameters; which you seem to be doing in your code.
No NN2 will not use L1 for its training, it just uses Out1 in its loss L2.
In the given scenario, Out2 and Out1 are inter dependent, Object/obstacle tracking and ego path estimation are correlated tasks, however NN1 (object tracking network) need not have the same loss as NN2, it just uses NN2-Out2 for its own loss (L1) calculation.
Think of it as an unsupervised cross task scenario.
@goku7 That’s true, but loss will still be back propagated through NN1 via L2. Even if the parameters aren’t updated, this is a little inefficient.
@PavanMV If NN2 shouldn’t use L1 for training and NN1 shouldn’t use L2 for its training, then their loss terms shouldn’t contain the other network’s output.
What I can imagine happening is that on your first L1 backwards call, the parameters of NN1 and NN2 are given gradients due to their output being utilized in the loss. But we don’t want NN2 to be updated via L1 (NN2 will keep those gradients and opt2 will utilize them). You can detach out2 so that the loss can still be computed (but gradients won’t flow through NN2), but adding a constant value won’t affect your gradients. Thus I don’t see why out2 is needed in L1.
Unless there exists an operation that utilizes out2 that will affect your gradients in NN1, I would argue that term is not needed in your loss term. The statement L1 = f1(out1) + f2(out2) suggests that this is the case.
It’s possible that you still need to compute that term for application purposes, but I don’t believe it should be included in your loss term that you perform back propagation on.