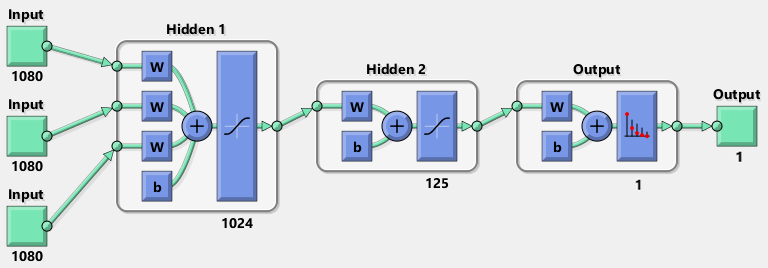
Hi!
I have been struggling with this code for a couple days. I couldn’t find many similar posts but the one’s I found have attributed to the code below.
I have 3 inputs that are three independent signals of a sensor. The rows represent a signal and the columns are values of that signal. On another file I have the target that is a column vector of 0 and 1’s. These 4 files are CSV.
I am having trouble passing three inputs to the network. From what I’ve gathered, it should occur in the forward section and then concatenated. The below code as is gives the error of:
mat1 and mat2 shapes cannot be multiplied (1080x20000 and 3x1)
import torch
import torch.nn as nn
import torch.optim as optim
import torch.autograd as autograd
import torch.nn.functional as F
#from torch.autograd import Variable
import pandas as pd
# Import Data
Input1 = pd.read_csv(r'....')
Input2 = pd.read_csv(r'....')
Input3 = pd.read_csv(r'....')
Target = pd.read_csv(r'...')
# Convert to Tensor
Input1_tensor = torch.tensor(Input1.to_numpy())
Input2_tensor = torch.tensor(Input2.to_numpy())
Input3_tensor = torch.tensor(Input3.to_numpy())
Target_tensor = torch.tensor(Target.to_numpy())
# Transpose to have signal as columns instead of rows
input1 = torch.transpose(Input1_tensor, 0, 1)
input2 = torch.transpose(Input2_tensor, 0, 1)
input3 = torch.transpose(Input3_tensor, 0, 1)
y = torch.transpose(Target_tensor, 0, 1)
# Define the model
class Net(nn.Module):
def __init__(self, num_inputs=3, num_outputs=1,hidden_dim=2):
# Initialize super class
super(Net, self).__init__()
# Add hidden layer
self.layer1 = nn.Linear(num_inputs,hidden_dim)
# Activation
self.sigmoid = torch.nn.Sigmoid()
# Add output layer
self.layer2 = nn.Linear(hidden_dim,num_outputs)
# Activation
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x1, x2, x3):
# implement the forward pass
#x = F.relu(self.layer1(x))
#x = F.sigmoid(self.layer2(x))
in1 = self.layer1(x1)
in2 = self.layer1(x2)
in3 = self.layer1(x3)
xyz = torch.cat((in1,in2,in3),1)
return xyz
# Network parameters
num_inputs = 3
num_hidden_layer_nodes = 100
num_outputs = 1
# Training parameters
num_epochs = 100
# Construct our model by instantiating the class defined above
model = Net(num_inputs, num_hidden_layer_nodes, num_outputs)
# Define loss function
loss_function = nn.MSELoss(reduction='sum')
# Define optimizer
optimizer = optim.SGD(model.parameters(), lr=1e-4)
for t in range(num_epochs):
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(input1, input2, input3)
# Compute and print loss
loss = loss_function(y_pred, y)
print(t, loss.item())
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
# Calculate gradient using backward pass
loss.backward()
# Update model parameters (weights)
optimizer.step()
I would greatly appreciate feedback!! (on this but any other thing related to the code is welcomed, i’m new!)