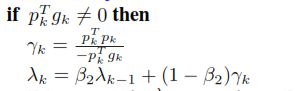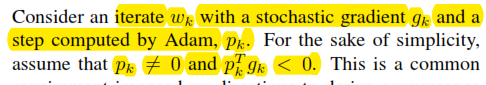Where gk is the gradient tensor and pk is the same shape tensor as gk. For example, if the gradient tensor has the shape (c,m,n) then its transpose tensor will have the shape is (n,m,c).
How can I do the multiplication between two tensors to get the scalar result? In that paper:
The author also told that pk different from 0 and the multiplication is smaller than 0.
I am not sure about this paper.
Typically, you can consider the parameters as an 1D array (vectorize the conv and fully connected layer parameters) and correspondingly the gradients will also be an 1D array.
Further, you can do p^T.g as normal inner product.
Would this work?
Or for gk shape (c,m,n) and pk transpose shape is (c,n,m) then multiply to get the result tensor shape is (c, n, n) (equal zero if all elements are zero)