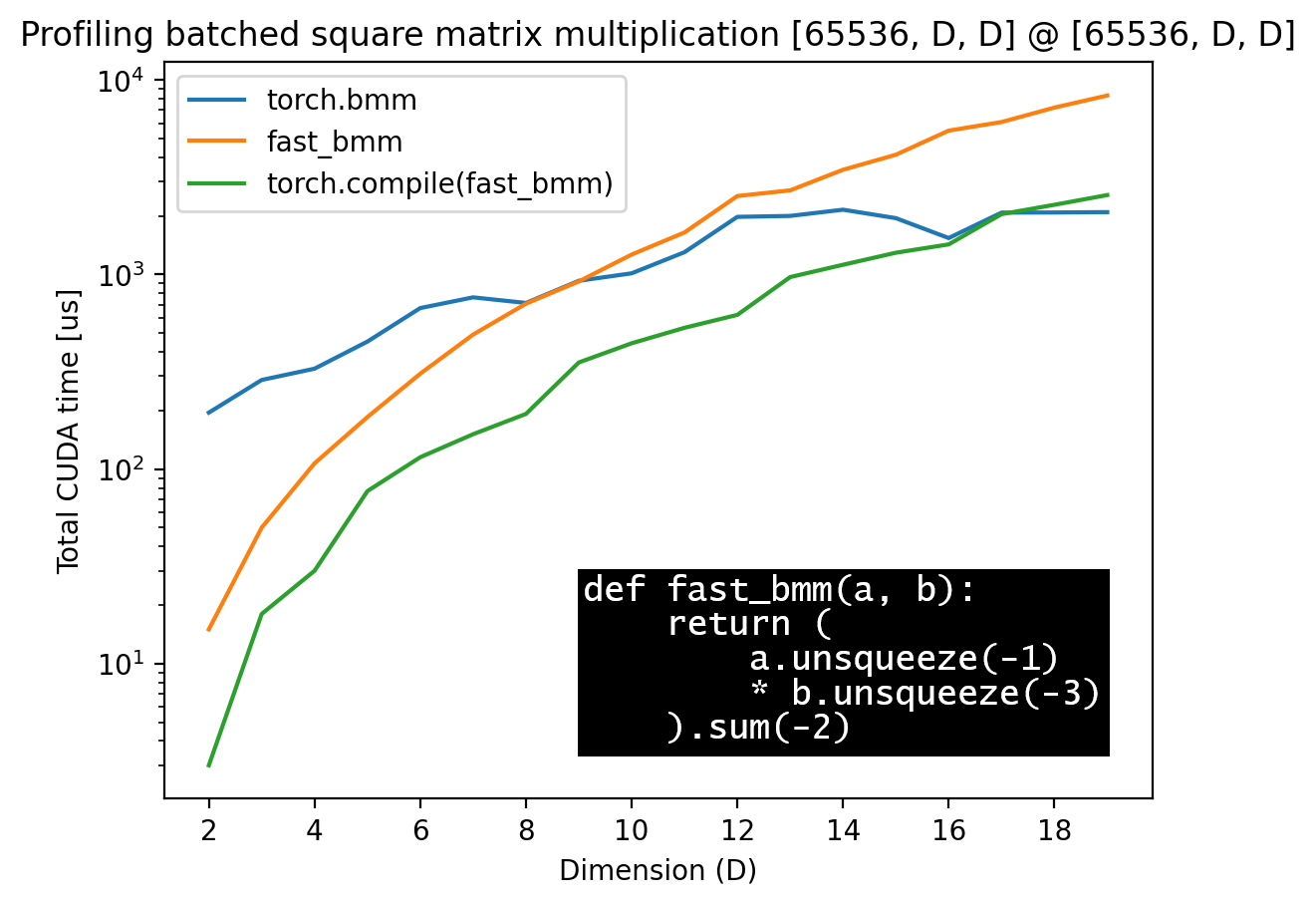
What’s the best way to multiply a lot of small matrices in pytorch? I.e., say I want to multiply two batches of 2x2 matrices, with a large batch size. I seem to be getting better results by explicitly writing out the matrix multiplication than by using torch.bmm. Example below:
import torch
def fast_2x2_bmm(a, b):
# There should be faster methods...
return torch.stack(
[
torch.stack(
[
a[..., 0, 0]*b[..., 0, 0] + a[..., 0, 1]*b[..., 1, 0],
a[..., 1, 0]*b[..., 0, 0] + a[..., 1, 1]*b[..., 1, 0],
],
dim=-1,
),
torch.stack(
[
a[..., 0, 0]*b[..., 0, 1] + a[..., 0, 1]*b[..., 1, 1],
a[..., 1, 0]*b[..., 0, 1] + a[..., 1, 1]*b[..., 1, 1],
],
dim=-1,
),
],
dim=-1,
)
fast_2x2_bmm = torch.compile(fast_2x2_bmm)
def fast_3x3_bmm(a, b):
# There should be faster methods...
return torch.stack(
[
torch.stack(
[
a[..., 0, 0]*b[..., 0, 0] + a[..., 0, 1]*b[..., 1, 0] + a[..., 0, 2]*b[..., 2, 0],
a[..., 1, 0]*b[..., 0, 0] + a[..., 1, 1]*b[..., 1, 0] + a[..., 1, 2]*b[..., 2, 0],
a[..., 2, 0]*b[..., 0, 0] + a[..., 2, 1]*b[..., 1, 0] + a[..., 2, 2]*b[..., 2, 0],
],
dim=-1,
),
torch.stack(
[
a[..., 0, 0]*b[..., 0, 1] + a[..., 0, 1]*b[..., 1, 1] + a[..., 0, 2]*b[..., 2, 1],
a[..., 1, 0]*b[..., 0, 1] + a[..., 1, 1]*b[..., 1, 1] + a[..., 1, 2]*b[..., 2, 1],
a[..., 2, 0]*b[..., 0, 1] + a[..., 2, 1]*b[..., 1, 1] + a[..., 2, 2]*b[..., 2, 1],
],
dim=-1,
),
torch.stack(
[
a[..., 0, 0]*b[..., 0, 2] + a[..., 0, 1]*b[..., 1, 2] + a[..., 0, 2]*b[..., 2, 2],
a[..., 1, 0]*b[..., 0, 2] + a[..., 1, 1]*b[..., 1, 2] + a[..., 1, 2]*b[..., 2, 2],
a[..., 2, 0]*b[..., 0, 2] + a[..., 2, 1]*b[..., 1, 2] + a[..., 2, 2]*b[..., 2, 2],
],
dim=-1,
),
],
dim=-1,
)
fast_3x3_bmm = torch.compile(fast_3x3_bmm)
def torch_bmm(a, b):
return torch.bmm(a, b)
torch_bmm = torch.compile(torch_bmm)
if __name__ == "__main__":
from torch.profiler import profile, record_function, ProfilerActivity
B = 262144
D = 2
if D not in [2, 3]: raise NotImplementedError()
fast_bmm = fast_2x2_bmm if D == 2 else fast_3x3_bmm
# run functions
torch_bmm(torch.randn([B, D, D]).cuda(), torch.randn([B, D, D]).cuda())
fast_bmm(torch.randn([B, D, D]).cuda(), torch.randn([B, D, D]).cuda())
mat0 = torch.randn([B, D, D]).cuda()
mat1 = torch.randn([B, D, D]).cuda()
assert torch.allclose(
torch_bmm(mat0, mat1),
fast_bmm(mat0, mat1),
atol=1e-4,
rtol=1e-4,
)
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
record_shapes=True,
) as prof:
torch.bmm(mat0, mat1) # warm up?
with record_function("bmm"):
torch.bmm(mat0, mat1)
with record_function("compiled bmm"):
torch_bmm(mat0, mat1)
with record_function("compiled fast bmm"):
fast_bmm(mat0, mat1)
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))
I get 886 us CUDA time for torch.bmm, but 22 us for explicitly writing out the multiplication.