Hello,
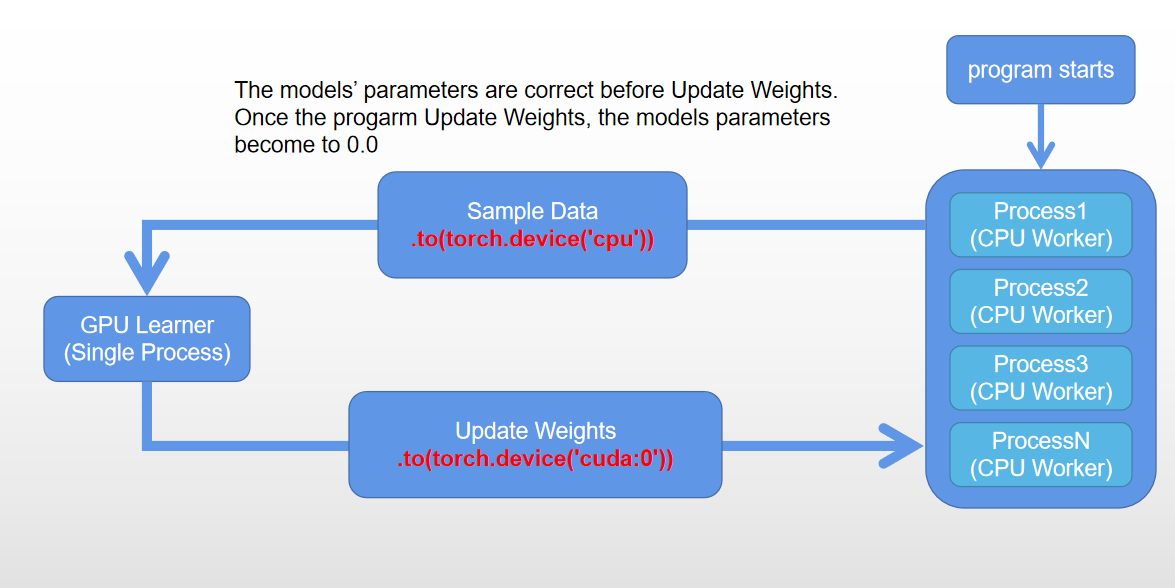
In order to improve the sampling efficiency I decide to use multiprocessing to do the sampling with CPU(model prediction also with cpu) and train the model with single a process by GPU.

The multiple rollout workers code as followed:
def multi_sampling(_env):
# _env.actor's and _env.critic's named_parameters() became all 0 **after training**.
# The parameters are correct before training
_env.env.reset()
agent = Agent(_env)
sample_res = agent.sampling()
return sample_res
env = CartPole() # _env has my actor model and critic model
process_pool = Pool(env.n_WORKER)
for sample_index in range(env.n_SAMPLES_PER_EPISODE):
res = process_pool.apply_async(multi_sampling, args=(env,))
res_dict[sample_index] = res
After training the models(update the weights of actor and critic), the model’s weights and biases becomes 0.0 in function multi_sampling. But the weights and biases are correct before my first training.
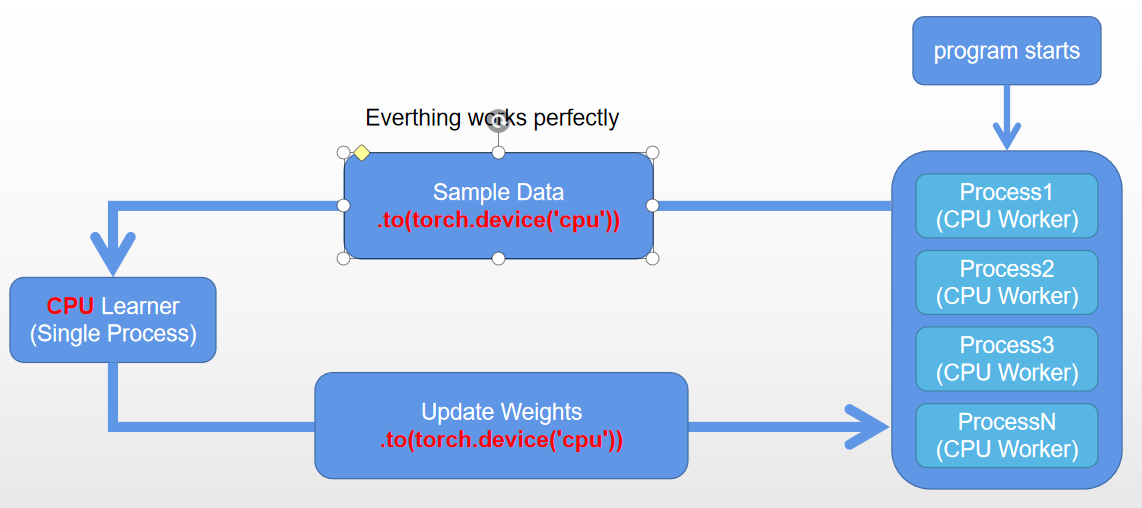
If I only use CPU to do the sampling and training, the results will just perfect which I could finish the cartpole task in 10 seconds (avg 195 rewards of continuous 100 episodes)
My question is, how do I sampling with CPU and training with GPU in a efficient and correct way?