Hello, I have custom map-style dataset created and I iterate with the native PyTorch Dataloader. I use num_workers = 1 for debugging purposes and understanding the bottlenecks with pytorch profiler. Here is what I see in PyTorch Profiler’s trace tab:
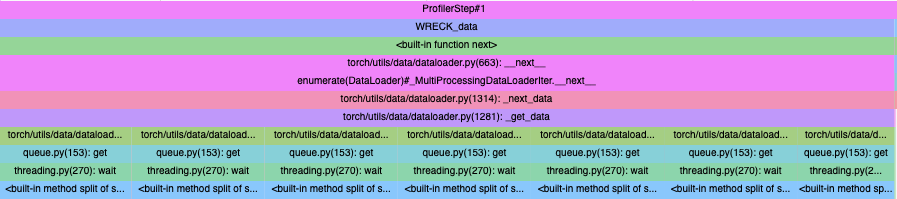
I’m confused why there are 7 different threads still created that wait for other thread to finish in each iteration of dataloader. Can someone help me understand and guide me how to definitely get a single process dataloader?