I am trying to build a simple encoder - decoder network on time-series data however I am not entirely sure if my implementation is correct.
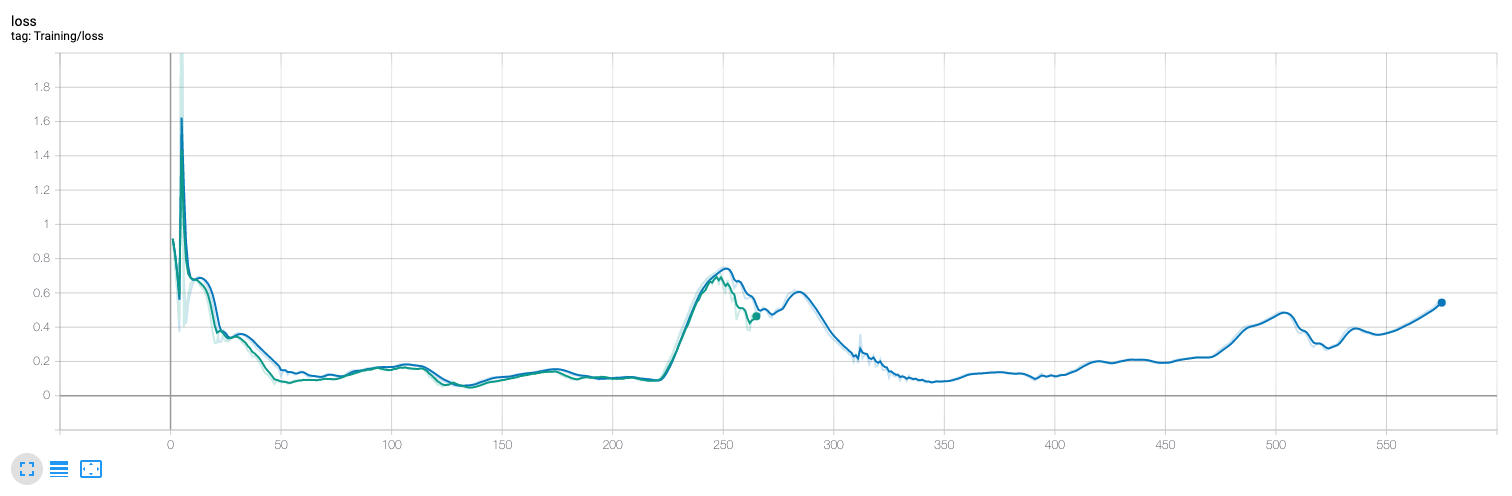
The training loss (MSE) fluctuates but overall appears to decrease over the first epoch, but then it stalls. Similarly validation error does not decrease after the first epoch
The basic model I’ve started with:
class Encoder(nn.Module):
def __init__(
self, number_of_features: int, sequence_length: int, hidden_size: int, num_layers: int, dropout: float
):
super(Encoder, self).__init__()
self.sequence_length = sequence_length
self.number_of_features = number_of_features
self.hidden_size = hidden_size
self.num_layers = num_layers
self.dropout_amount = dropout
self.lstm = nn.LSTM(
input_size=number_of_features,
hidden_size=hidden_size,
num_layers=num_layers,
dropout=dropout
)
def init_hidden(self, batch_size, device='cpu'):
return (torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device),
torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device))
def forward(self, data):
_, hidden = self.lstm(data, self.hidden)
return hidden
class Decoder(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers, dropout):
super(Decoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.dropout = dropout
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, dropout=dropout)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, point_in_time, hidden):
output, hidden = self.lstm(point_in_time, hidden)
output = self.out(output[-1])
return output, hidden
Based on the single feature that I have to predict and the time, I’ve crafted a few extra features, such as sin/cos for the time, and a moving average thus creating a DataFrame with 4 columns.
Afterwards I used sliding window to create sequences of length 20 (for testing) with the following code:
def _create_sequences(data: np.ndarray, window: int = 20) -> (np.array, np.array):
length = len(data)
sequences = []
for index in range(length - window):
end_window_index = index + window
sequence = data[index:end_window_index]
next_in_sequence = data[index + 1:end_window_index + 1][:, 0]
sequences.append([sequence, next_in_sequence])
return sequences
At this point my dataset is compromised of a list of tupples each containing the sequence (X) (20 sequence length x 4 features) and the next sequence (t+1) (Y) (20).
I split the data to train/val sets (80/20) and push them to the DataLoader to get the data in batches of size 25.
The training section is the following:
encoder = Encoder(number_of_features=4, sequence_length=20, hidden_size=256, num_layers=2, dropout=0.3)
decoder = Decoder(input_size=1, hidden_size=256, output_size=1, num_layers=2, dropout=0.3)
def train(loader, current_epoch, teacher_forcing_ratio=0.75):
encoder.train()
decoder.train()
total_loss = 0
encoder.hidden = encoder.init_hidden(args.batch_size, device=device)
for i, batch in enumerate(loader):
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
x = batch[0] # (Shape 25 x 20 x 4)
y = batch[1] # (Shape 25 x 20)
x = x.to(device)
y = y.to(device)
x = x.permute(1, 0, 2) # Change the order to pass it to the LSTM Shape now is 20 x 25 x 4
y = y.permute(1, 0) # Change the order to 20 x 25
max_sequence, batch_size = y.shape
hidden = encoder(x)
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
# Create initial start value/token
input = torch.tensor([[0.0]] * batch_size, dtype=torch.float).to(device)
# Convert (batch_size, output_size) to (seq_len, batch_size, output_size)
input = input.unsqueeze(0)
sequence_total_loss = 0
for seq_idx in range(max_sequence):
output, hidden = decoder(input, hidden)
if use_teacher_forcing:
input = y[seq_idx].view(1, -1, 1)
else:
input = output.unsqueeze(0)
sequence_total_loss += criterion(output.view(-1), y[seq_idx])
sequence_total_loss.backward()
cur_loss = sequence_total_loss / max_sequence
total_loss += cur_loss
encoder_optimizer.step()
decoder_optimizer.step()
I’ve used two Adam optimizers (one for the encoder and one for the decoder). I’ve also tried changing the model size, sequence length, batch size but it didn’t appear to make a difference
If anyone could take the time and give me any hints on where I may have got it wrong I would very much appreciate it.