This post pertains to performing multivariate (predicting more than 1 output) regression in PyTorch. Say we are predicting N-variables, so our output layer has N nodes. The objective function used is the MSE objective function.
cost_func = nn.MSELoss()
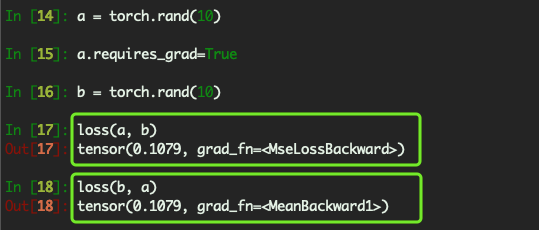
When training, we supply 2 arguments to cost_func(arg_1, arg_2), where arg_1 is the labels of the training samples, and arg_2 is the output of the forward pass. Should arg_1 and arg_2 bot have N columns, or should they be cast to 1 column tensors?
Input: (N,∗) where * means, any number of additional dimensions
Target: (N,∗), same shape as the input
The first argument is Input and second is the Target, so you are passing them in a wrong order.
And, the size of the Input and Target should be the same no matter what shape they are. Like 10 and 10 is OK, 10x30 and 10x30 is OK, but 10x30 and 10x40 is not OK.
You’re simply computing the MSE, which is the sum of the squares of the differences between input and target. It doesn’t matter if you’re computing the differences by doing input - target, or target - input since you’re squaring the differences.
Yeah mathematically they do not have a difference. But we are at PyTorch which more of a software engineering field and the document has told us that what are the first and second parameters so it’s a good idea to follow the document.
The actual differences are the grad computing function are not the same.
I have tested it the results(Grad) are the same though.