Hi everyone. I’m trying to implement a transformer for pre-training on partially masked multivariate time-series data. The model input is of the type (batch size, num signals, seq len), where there are 3 signals and they all have the same length (240 time steps). The loss function used is the RMSE between only the masked values and the corresponding predictions. The problem is that the predictions are totally wrong. This is my model:
class LearnablePositionalEncoding(nn.Module):
def __init__(self, segment_length, d_model, dropout):
super(LearnablePositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
self.pe = nn.Parameter(torch.empty(segment_length, 1, d_model))
nn.init.uniform_(self.pe, -0.02, 0.02)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
class MyEncoderLayer(nn.modules.Module):
def __init__(self, d_model, nhead, dim_feedforward, dropout=0.1):
super(MyEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model)
self.norm1 = BatchNorm1d(d_model, eps=1e-5)
self.norm2 = BatchNorm1d(d_model, eps=1e-5)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.activation = F.gelu
def forward(self, data: Tensor, src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None, is_causal: Optional[bool] = None) -> Tensor:
# Self-attention
data2 = self.self_attn(data, data, data, attn_mask=src_mask, key_padding_mask=src_key_padding_mask, is_causal=is_causal)[0]
# Add & Norm
data = data + self.dropout1(data2) # [segment_length, batch_size, d_model]
data = data.permute(1, 2, 0) # [batch_size, d_model, segment_length]
data = self.norm1(data)
data = data.permute(2, 0, 1) # [segment_length, batch_size, d_model]
# Feed-forward
data2 = self.linear2(self.dropout(self.activation(self.linear1(data))))
# Add & Norm
data = data + self.dropout2(data2) # [segment_length, batch_size, d_model]
data = data.permute(1, 2, 0) # [batch_size, d_model, segment_length]
data = self.norm2(data)
data = data.permute(2, 0, 1) # [segment_length, batch_size, d_model]
return data
class TSTransformer(nn.Module):
def __init__(self, num_signals, segment_length, iperparametri, device, pe_type='learnable'):
super(TSTransformer, self).__init__()
self.num_signals = num_signals
self.segment_length = segment_length
self.d_model = iperparametri['d_model']
self.dropout = iperparametri['dropout']
self.num_layers = iperparametri['num_layers']
self.num_heads = iperparametri['num_heads']
self.device = device
self.project_inp = nn.Linear(self.num_signals, self.d_model)
if pe_type == 'learnable':
self.pos_enc = LearnablePositionalEncoding(self.segment_length, self.d_model, self.dropout)
elif pe_type == 'fixed':
self.pos_enc = FixedPositionalEncoding(self.segment_length, self.d_model, self.dropout, self.device)
encoder_layer = MyEncoderLayer(self.d_model, self.num_heads, self.d_model, self.dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, self.num_layers)
self.output_layer = nn.Linear(self.d_model, self.num_signals)
self.act = F.gelu
self.dropout1 = nn.Dropout(self.dropout)
def forward(self, data):
# [batch_size, num_signals, segment_length]
inp = data.permute(2, 0, 1) # [segment_length, batch_size, num_signals]
inp = self.project_inp(inp) * math.sqrt(self.d_model) # [segment_length, batch_size, d_model]
inp = self.pos_enc(inp) # Aggiunta del positional encoding
output = self.transformer_encoder(inp) # [segment_length, batch_size, d_model]
output = self.act(output) # Funzione di attivazione
output = output.permute(1, 0, 2) # [batch_size, segment_length, d_model]
output = self.dropout1(output) # Dropout
output = self.output_layer(output) # [batch_size, segment_length, num_signals]
output = output.permute(0, 2, 1) # [batch_size, num_signals, segment_length]
return output # [batch_size, num_signals, segment_length]
For each epoch I carry out a training activity and a validation activity as shown below:
def train_pretrain_model(model, dataloader, num_signals, segment_length, iperparametri, optimizer, device):
model.train()
train_loss = 0.0
num_batches = len(dataloader)
progress_bar = tqdm(total=num_batches, desc="Train batch analizzati")
for batch in dataloader:
optimizer.zero_grad()
masks = generate_masks(iperparametri['batch_size'], iperparametri['masking_ratio'],
iperparametri['lm'], num_signals, segment_length, device)
masked_batch = batch * masks
predictions = model(masked_batch)
loss = pretraining_loss(predictions, batch, masks)
loss.backward()
optimizer.step()
train_loss += loss.item()
progress_bar.update(1)
progress_bar.close()
return train_loss / num_batches, model
def validate_pretrain_model(model, dataloader, num_signals, segment_length, iperparametri, device):
model.eval()
val_loss = 0.0
num_batches = len(dataloader)
with torch.no_grad():
progress_bar = tqdm(total=num_batches, desc="Val batch analizzati")
for batch in dataloader:
masks = generate_masks(iperparametri['batch_size'], iperparametri['masking_ratio'],
iperparametri['lm'], num_signals, segment_length, device)
masked_batch = batch * masks
predictions = model(masked_batch)
loss = pretraining_loss(predictions, batch, masks)
val_loss += loss.item()
progress_bar.update(1)
progress_bar.close()
return val_loss / num_batches, model
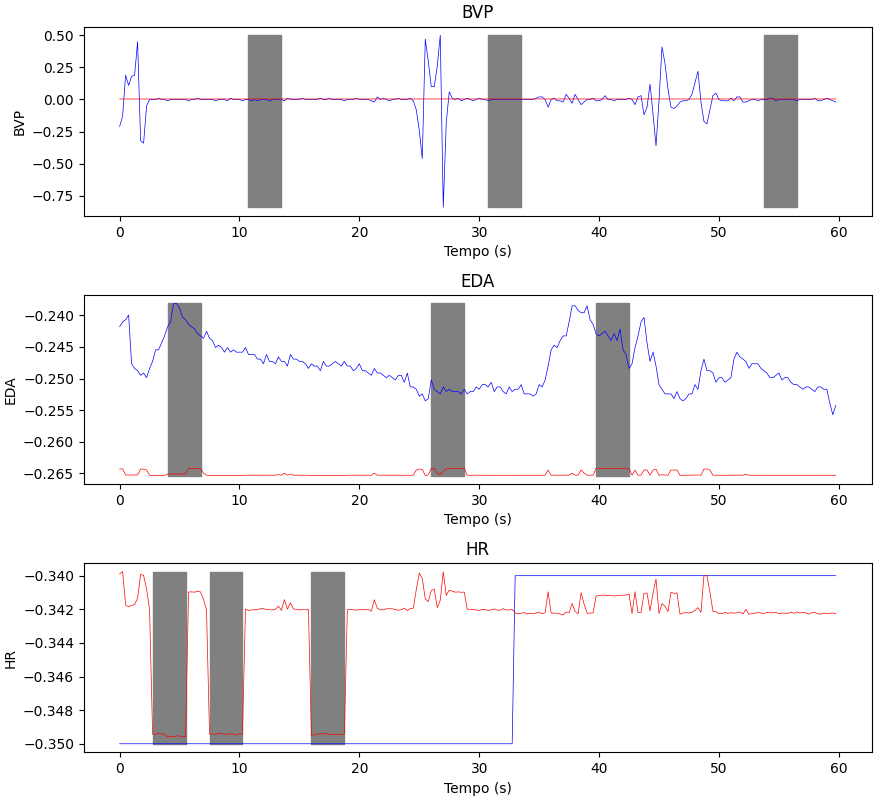
The next image describes how the model’s predictions are incorrect. The blue lines are the actual values, the red lines are the predictions, the gray areas are the masked sections.