Hi,
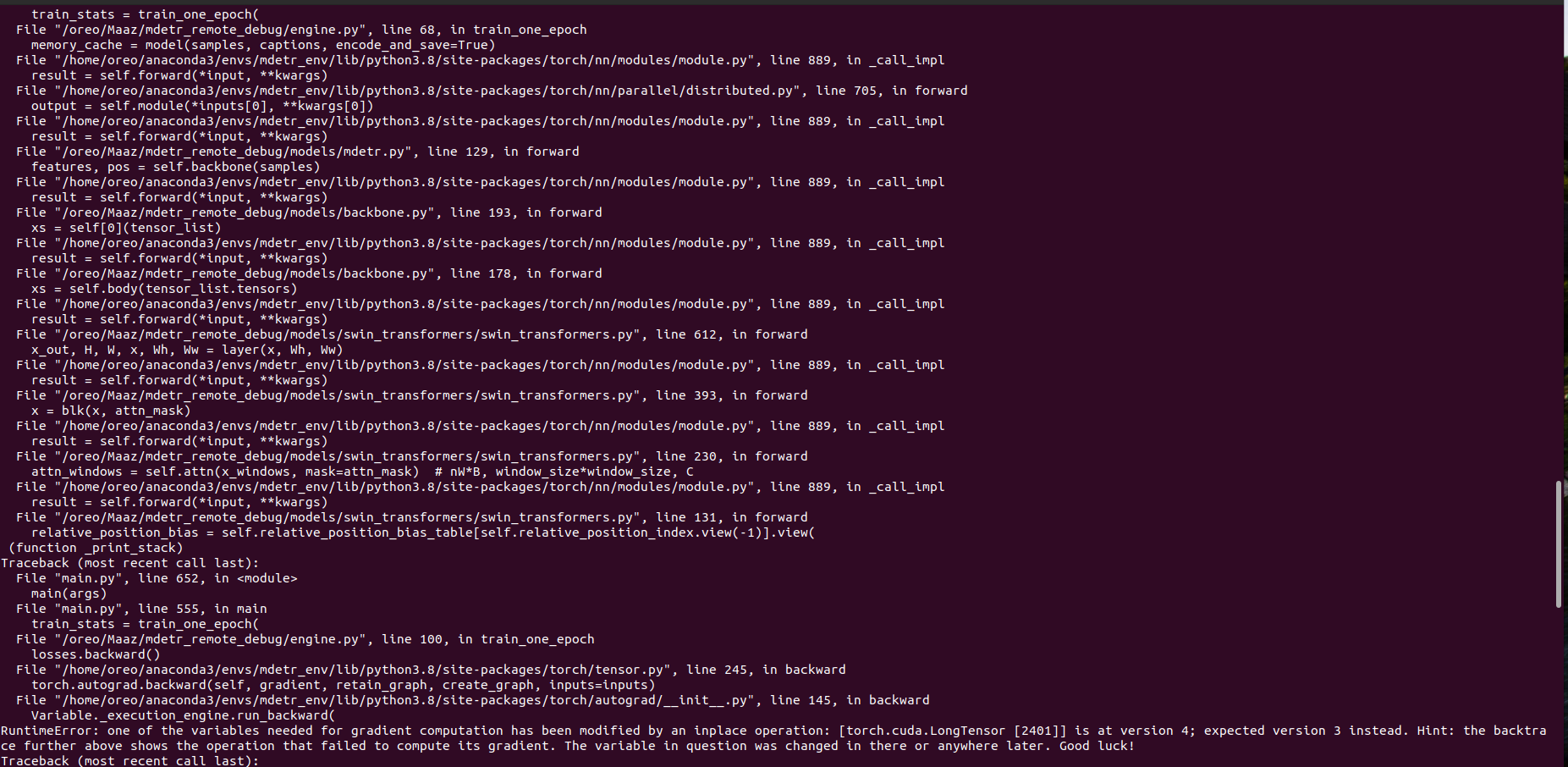
I am trying to use swin transformer backbone with my modified mdetr codebase. The code is running perfectly fine on a single GPU but giving attached error when running on multiple GPUs using torch.distributed.launce.
I tried setting up torch.autograd.set_detect_anomaly(True) and it pointed out to the line 133 of swin_transformers.py. Note that the error goes away if I set the requires_grad=False for relative_position_bias_table parameter.
I am using torch 1.8.0+cu11 on NVIDIA A6000 GPUs. I will appreciate any help to resolve this issue. Thank You
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu, Yutong Lin, Yixuan Wei
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
""" Multilayer perceptron."""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
# (requires_grad=False to fix the multi-gpu training issue for downstream task.)
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads), requires_grad=False)
# 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] = relative_coords[:, :, 0] + self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] = relative_coords[:, :, 1] + self.window_size[1] - 1
relative_coords[:, :, 0] = relative_coords[:, :, 0] * (2 * self.window_size[1] - 1)
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
""" Forward function.
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformerBlock(nn.Module):
""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.H = None
self.W = None
def forward(self, x, mask_matrix):
""" Forward function.
Args:
x: Input feature, tensor size (B, H*W, C).
H, W: Spatial resolution of the input feature.
mask_matrix: Attention mask for cyclic shift.
"""
B, L, C = x.shape
H, W = self.H, self.W
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
attn_mask = mask_matrix
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchMerging(nn.Module):
""" Patch Merging Layer
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
""" Forward function.
Args:
x: Input feature, tensor size (B, H*W, C).
H, W: Spatial resolution of the input feature.
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of feature channels
depth (int): Depths of this stage.
num_heads (int): Number of attention head.
window_size (int): Local window size. Default: 7.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self,
dim,
depth,
num_heads,
window_size=7,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
norm_layer=nn.LayerNorm,
downsample=None,
use_checkpoint=False):
super().__init__()
self.window_size = window_size
self.shift_size = window_size // 2
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x, H, W):
""" Forward function.
Args:
x: Input feature, tensor size (B, H*W, C).
H, W: Spatial resolution of the input feature.
"""
# calculate attention mask for SW-MSA
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # 1 Hp Wp 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt = cnt + 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
for blk in self.blocks:
blk.H, blk.W = H, W
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
if self.downsample is not None:
x_down = self.downsample(x, H, W)
Wh, Ww = (H + 1) // 2, (W + 1) // 2
return x, H, W, x_down, Wh, Ww
else:
return x, H, W, x, H, W
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
Args:
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
"""Forward function."""
# padding
_, _, H, W = x.size()
if W % self.patch_size[1] != 0:
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1]))
if H % self.patch_size[0] != 0:
x = F.pad(x, (0, 0, 0, self.patch_size[0] - H % self.patch_size[0]))
x = self.proj(x) # B C Wh Ww
if self.norm is not None:
Wh, Ww = x.size(2), x.size(3)
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
x = x.transpose(1, 2).view(-1, self.embed_dim, Wh, Ww)
return x
class SwinTransformer(nn.Module):
""" Swin Transformer backbone.
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
pretrain_img_size (int): Input image size for training the pretrained model,
used in absolute postion embedding. Default 224.
patch_size (int | tuple(int)): Patch size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
depths (tuple[int]): Depths of each Swin Transformer stage.
num_heads (tuple[int]): Number of attention head of each stage.
window_size (int): Window size. Default: 7.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
drop_rate (float): Dropout rate.
attn_drop_rate (float): Attention dropout rate. Default: 0.
drop_path_rate (float): Stochastic depth rate. Default: 0.2.
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False.
patch_norm (bool): If True, add normalization after patch embedding. Default: True.
out_indices (Sequence[int]): Output from which stages.
frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
-1 means not freezing any parameters.
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self,
pretrain_img_size=224,
patch_size=4,
in_chans=3,
embed_dim=96,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
norm_layer=nn.LayerNorm,
ape=False,
patch_norm=True,
out_indices=(0, 1, 2, 3),
frozen_stages=-1,
use_checkpoint=False):
super().__init__()
self.pretrain_img_size = pretrain_img_size
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.out_indices = out_indices
self.frozen_stages = frozen_stages
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
# absolute position embedding
if self.ape:
pretrain_img_size = to_2tuple(pretrain_img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [pretrain_img_size[0] // patch_size[0], pretrain_img_size[1] // patch_size[1]]
self.absolute_pos_embed = nn.Parameter(
torch.zeros(1, embed_dim, patches_resolution[0], patches_resolution[1]))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
num_features = [int(embed_dim * 2 ** i) for i in range(self.num_layers)]
self.num_features = num_features
# add a norm layer for each output
for i_layer in out_indices:
layer = norm_layer(num_features[i_layer])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
self._freeze_stages()
def _freeze_stages(self):
if self.frozen_stages >= 0:
self.patch_embed.eval()
for param in self.patch_embed.parameters():
param.requires_grad = False
if self.frozen_stages >= 1 and self.ape:
self.absolute_pos_embed.requires_grad = False
if self.frozen_stages >= 2:
self.pos_drop.eval()
for i in range(0, self.frozen_stages - 1):
m = self.layers[i]
m.eval()
for param in m.parameters():
param.requires_grad = False
def init_weights(self, pretrained=None):
"""Initialize the weights in backbone.
Args:
pretrained (str, optional): Path to pre-trained weights.
Defaults to None.
"""
def _init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
if isinstance(pretrained, str):
self.apply(_init_weights)
load_pretrained_weights(self, pretrained, strict=False)
elif pretrained is None:
self.apply(_init_weights)
else:
raise TypeError('pretrained must be a str or None')
def forward(self, x):
"""Forward function."""
x = self.patch_embed(x)
Wh, Ww = x.size(2), x.size(3)
if self.ape:
# interpolate the position embedding to the corresponding size
absolute_pos_embed = F.interpolate(self.absolute_pos_embed, size=(Wh, Ww), mode='bicubic')
x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww C
else:
x = x.flatten(2).transpose(1, 2)
x = self.pos_drop(x)
outs = []
for i in range(self.num_layers):
layer = self.layers[i]
x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)
if i in self.out_indices:
norm_layer = getattr(self, f'norm{i}')
x_out = norm_layer(x_out)
out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()
outs.append(out)
return tuple(outs)
def train(self, mode=True):
"""Convert the model into training mode while keep layers freezed."""
super(SwinTransformer, self).train(mode)
self._freeze_stages()
def load_pretrained_weights(model, checkpoints_path, strict=False):
print(f"Loading swin backbone checkpoints from {checkpoints_path}.")
checkpoints = torch.load(checkpoints_path)
checkpoints = checkpoints["model"]
status = model.load_state_dict(checkpoints, strict=strict)
print(f"Missing Keys: {status.missing_keys}\nUnexpected Keys: {status.unexpected_keys}")