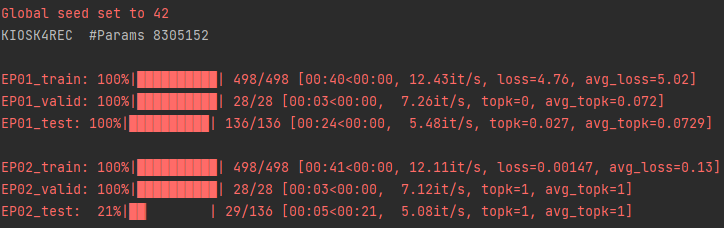
Hello Pytorch community!
I am trying to create a recommender system and my data is in the form of a graph. Even if I had tried too much, I couldn’t figure out the reason that gives me full accuracy and minimum loss in just 2nd epoch. I would be more than thankful if someone can point out my mistake.
Code is the following:
import torch.nn as nn
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
from sklearn.metrics import top_k_accuracy_score
from pytorch_lightning.utilities.seed import seed_everything
from dataset import Evaluate_Dataset
from models import Evaluate4rec, Kiosk4Rec, Bert4Rec, GRU4Rec
def load_model(name, args, vocab_size):
model = None
if name == 'kiosk4rec':
model = Kiosk4Rec(args=args, vocab_size=vocab_size)
elif name == 'bert4rec':
model = Bert4Rec(args=args, vocab_size=vocab_size)
elif name == 'gru4rec':
model = GRU4Rec(args=args, vocab_size=vocab_size)
print(f'{name.upper():10s} #Params {sum([p.numel() for p in model.parameters()])}\n')
return model
if __name__ == "__main__":
args = argparse.ArgumentParser()
args.add_argument('--seed', default=42)
args.add_argument('--device', default=0)
args.add_argument('--runs', default=1)
args.add_argument('--epochs', default=100)
args.add_argument('--lr', default=0.0001)
args.add_argument('--batch_size', default=128)
args.add_argument('--embed_size', default=512)
args.add_argument('--num_layers', default=4)
args.add_argument('--num_heads', default=8)
args.add_argument('--hidden_size', default=512)
args.add_argument('--dropout', default=0.2)
args = args.parse_args()
seed_everything(args.seed)
device = f'cuda:{args.device}' if torch.cuda.is_available() else 'cpu'
# Load DataLoader
vocab = pickle.load(open(os.getcwd() + '/dataset/transaction/vocab.pkl', 'rb'))
transaction = {
'train': pickle.load(open(os.getcwd() + '/dataset/transaction/train.pkl', 'rb')),
'valid': pickle.load(open(os.getcwd() + '/dataset/transaction/valid.pkl', 'rb')),
'test': pickle.load(open(os.getcwd() + '/dataset/transaction/test.pkl', 'rb'))
}
dataloader = {
'train': DataLoader(
Evaluate_Dataset(transaction['train'], vocab), batch_size=args.batch_size, shuffle=True
),
'valid': DataLoader(
Evaluate_Dataset(transaction['valid'], vocab), batch_size=args.batch_size
),
'test': DataLoader(
Evaluate_Dataset(transaction['test'], vocab), batch_size=args.batch_size
)
}
# Load Model
model = load_model(name='bert4rec', args=args, vocab_size=vocab['size']).to(device)
evaluater = Evaluate4rec(model).to(device)
# Train & Valid & Test
for run in range(1, args.runs+1):
evaluater.reset_parameters()
optimizer = torch.optim.Adam(params=evaluater.parameters(), lr=args.lr)
for epoch in range(1, args.epochs+1):
for task in ['train']:
evaluater.train()
avg_loss = 0.
batch_iter = tqdm(enumerate(dataloader[task]), desc=f'EP{epoch:02d}_{task}', total=len(dataloader[task]))
for i, batch in batch_iter:
batch = {key: value.to(device) for key, value in batch.items()}
outputs = evaluater(batch)
outputs = torch.stack([output[list(batch['transaction'][i]).index(1)] for i, output in enumerate(outputs)])
loss = nn.CrossEntropyLoss()(outputs, batch['label'])
avg_loss += loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_iter.set_postfix({'loss': loss.item(), 'avg_loss': avg_loss.item() / (i+1)})
for task in ['valid', 'test']:
evaluater.eval()
avg_topk = 0.
batch_iter = tqdm(enumerate(dataloader[task]), desc=f'EP{epoch:02d}_{task}', total=len(dataloader[task]))
for i, batch in batch_iter:
batch = {key: value.to(device) for key, value in batch.items()}
with torch.no_grad():
outputs = evaluater(batch)
outputs = torch.stack([output[list(batch['transaction'][i]).index(1)] for i, output in enumerate(outputs)])
topk = top_k_accuracy_score(batch['label'].cpu(), outputs.cpu(), k=1, labels=range(vocab['size']))
avg_topk += topk
batch_iter.set_postfix({'topk': topk, 'avg_topk': avg_topk / (i+1)})