Hi,
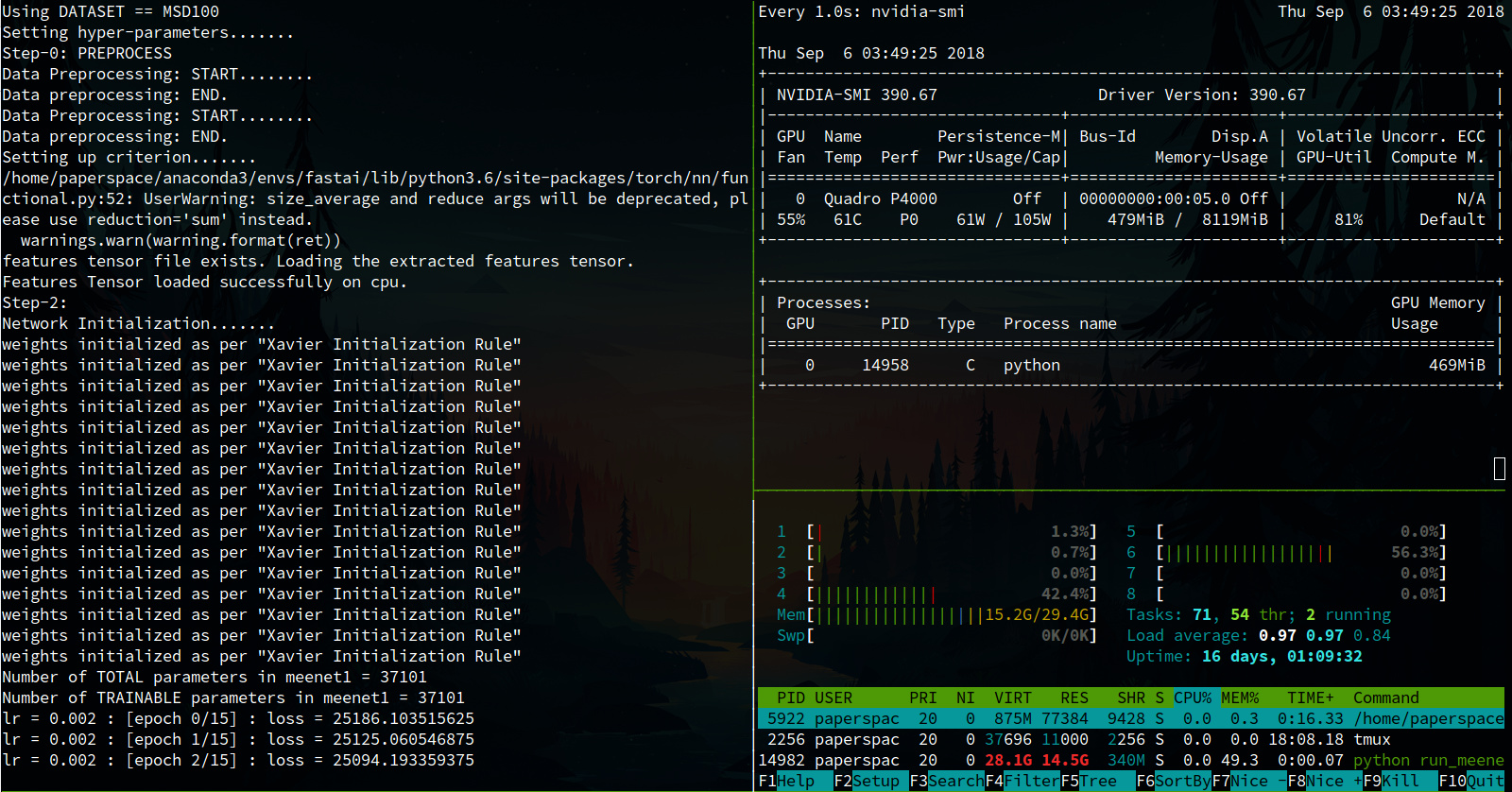
I’m using Convolutional Autoencoder Network. While training my CPU RAM (30GB) is getting fully used in just 20 epochs but my GPU memory (8GB) is used only 5%.
How should I approach to use my GPU better and reduce CPU memory usage.
Thanks
Hi,
I’m using Convolutional Autoencoder Network. While training my CPU RAM (30GB) is getting fully used in just 20 epochs but my GPU memory (8GB) is used only 5%.
How should I approach to use my GPU better and reduce CPU memory usage.
Thanks
would be better if you comment on how you load your data, if you are using standard data loaders of pytorch, or writing your own, what is your data(images, videos, text) etc. Basically if you give more info or better your code, the awesome ppl here would be able to help you out
Here is my code snippet which is possibly leading to CPU memory increase.
def train_cuda(device, dataset_name, audio_channel, data_feats_tensor, blueprint_input, criterion, num_epochs, learning_rates, lr_decay_rate, lr_decay_epoch_size, optim_hyperparams, reg_strengths=0.0, batch_size=1):
print('Network Initialization.......')
model_meenet1 = meenet1.MeeAutoEncoder()
model_meenet1.cuda()
# Initializing network weights and bias
model_meenet1.apply(weights_init)
loss_history = {}
num_train = data_feats_tensor.shape[1]
for m_lr in learning_rates:
loss_history[m_lr] = []
for epoch in range(num_epochs):
optimizer = torch.optim.Adam(params=model_meenet1.parameters(),
lr=m_lr,
betas=(optim_hyperparams['adam']['beta_1'], optim_hyperparams['adam']['beta_2']),
eps=optim_hyperparams['adam']['epsilon'],
weight_decay=optim_hyperparams['adam']['weight_decay']
)
running_loss = 0.0
for i in range(num_train):
train_input_tensor = data_feats_tensor[0,i,:,:].cuda().view_as(blueprint_input) # torch.Size([1, 1, 1025, 15])
train_label_tensor = data_feats_tensor[1,i,:,:].cuda().view_as(blueprint_input) # torch.Size([1, 1, 1025, 15])
optimizer.zero_grad()
pred_label_tensor = model_meenet1(train_input_tensor) # torch.Size([1, 1, 1025, 15])
loss = criterion(pred_label_tensor, train_label_tensor)
loss.backward()
optimizer.step()
running_loss += loss
# del train_input_tensor
# del train_label_tensor
# gc.collect() # garbage collection
loss_history[m_lr].append(running_loss/num_train)
print('lr = {} : [epoch {}/{}] : loss = {}'.format(m_lr, epoch, num_epochs, loss_history[m_lr][-1]))
gc.collect() # garbage collection
return loss_history
##############################################
When I’m calling this function the argument data_feats_tensor is a cpu tensor (i.e. it is the tensor was previously stored in CPU and now I’m just loading it). Later (s you can see in code above) I’m converting pieces of this tensor into CUDA tensor to use on GPU, but seems like it is never used in GPU.
Here is a snapshot of my tmux session.
You are storing the computation graph using this line of code:
running_loss += loss
Change it to running_loss += loss.item() and try it again.
Thanks a lot, @ptrblck. It works like a charm. 
I tried everything but I was just missing loss.