TL;DR
I got 30% token prediction accuracy for pretraining GPT2. Is it normal accuracy?
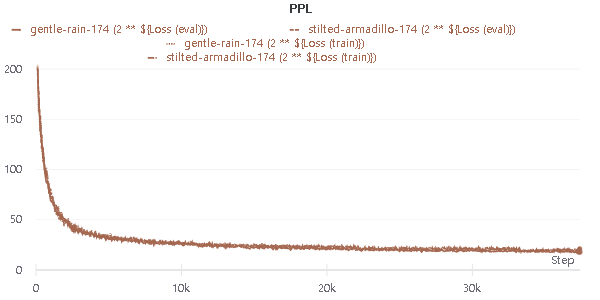
The Loss was about 4.2, The PPL was about 19
(Tools: Huggingface GPT2, ByteBPE, Deepspeed)
This is my report for pre-training gpt2 with conversational sentence
Because of short utterance, I only trained for short ‘nctx’. This is my configuration for gpt2
# 24 layer, 16 head, 1024 embed,
kogpt2_config_345m = {
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"n_ctx": 64,
"n_embd": 1024,
"n_head": 16,
"n_layer": 24,
"n_positions": 64,
"vocab_size": 32000,
"activation_function": "gelu"
}
Also, the vocab is huggingface byte-level BPE and the model is huggingface GPT2LMHeadModel
And I trained the model with RTX8000 * 2 (which are 48GB*2)
Also, I used deepspeed with thisconfig
{
"train_batch_size": 1792,
"gradient_accumulation_steps": 2,
"optimizer": {
"type": "Adam",
"params": {
"lr": 1e-3
}
},
"fp16": {
"enabled": true,
"loss_scale": 0
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": false,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": false,
"cpu_offload": true
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 1e-3,
"warmup_num_steps": 4000
}
}
}
And my loss is
outputs = self.model_engine(token_ids) # (batch_size, max_len, embed_dims)
logits = outputs.logits
# Cross Entropy
loss = self.loss_function(logits.transpose(2, 1), label) # (batch_size, max_len)
mask = mask.half()
loss = loss.half()
...
const = torch.zeros(1).to(args.local_rank).half()
masked_loss = torch.where(mask == 1, loss, const)
# Max integer of fp16 is 65536.0
# The sum of loss should not be larger than the max integer
# Thus, the loss is averaged for sequence length first and those values are averaged on batch size
sub_loss = masked_loss.sum(dim=-1)
sub_mask = mask.sum(dim=-1)
sub_avg = sub_loss/sub_mask
loss_avg = sub_avg.mean()
self.model_engine.backward(loss_avg)
Because of fp16 limitations, I used mean of mean to get global mean of loss batch
And finally, I got this result (Loss (eval) ~= 4.2, Acc (eval) ~= 30%, PPL ~= 19 )
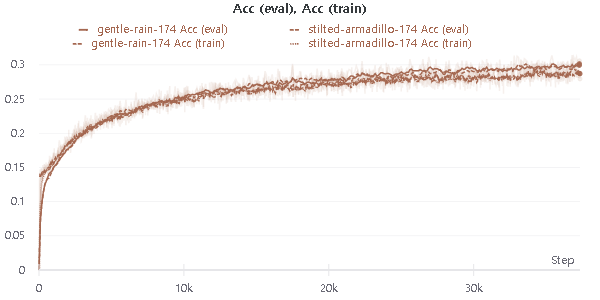
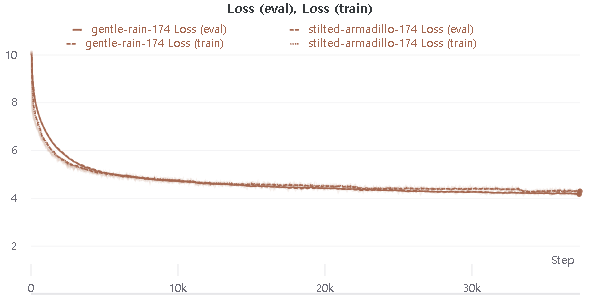
Is it normal to get 30% accuracy on prediction token?
The PPL is similar with that of the GPT2, which is known as 17
Thank you.