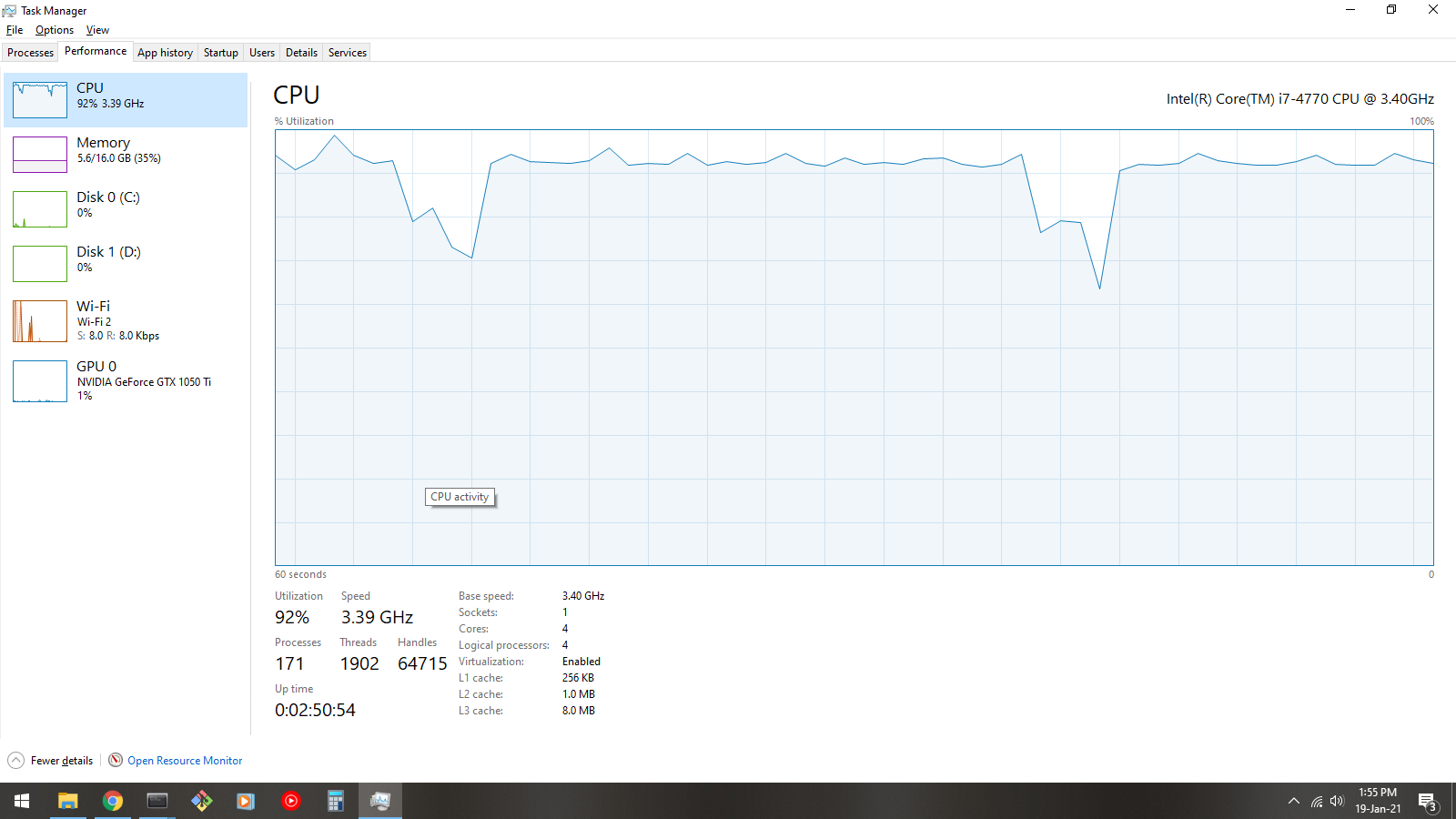
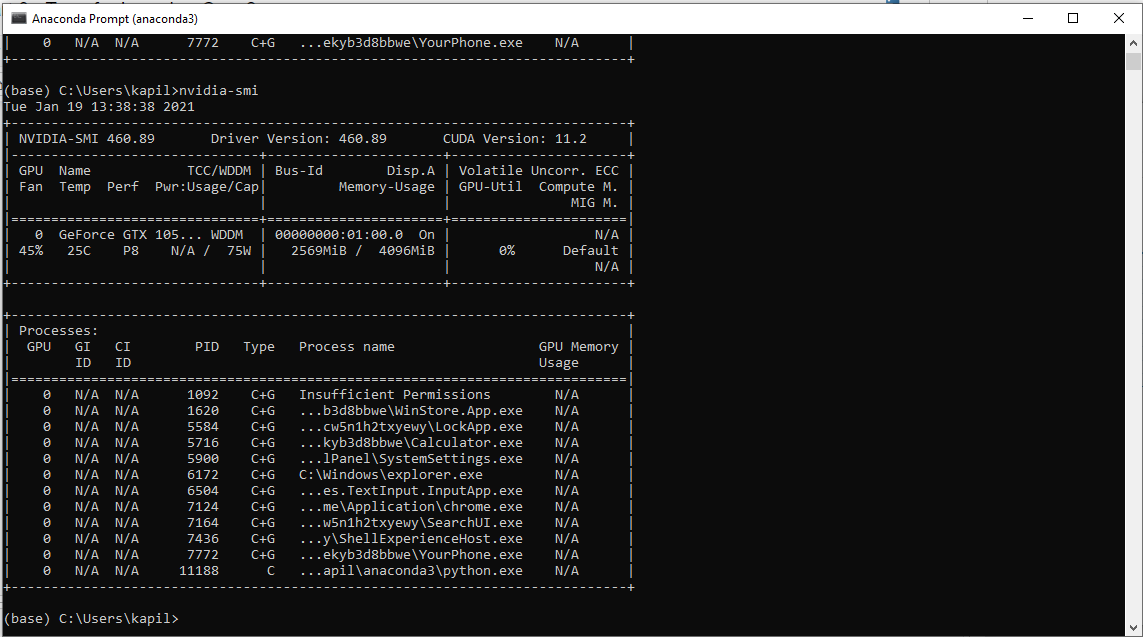
I have 16gb ram, MSI 1050ti graphics card, intel 4770 processor.
though I have already installed
- CUDA=11.0
- CUDNN=8.0.5
- PYTORCH= 1.7
- Windows=10
import torch
import sys
print('__Python VERSION:', sys.version)
print('__pyTorch VERSION:', torch.__version__)
print('__CUDA VERSION', )
from subprocess import call
# call(["nvcc", "--version"]) does not work
! nvcc --version
print('__CUDNN VERSION:', torch.backends.cudnn.version())
print('__Number CUDA Devices:', torch.cuda.device_count())
print('__Devices')
# call(["nvidia-smi", "--format=csv", "--query-gpu=index,name,driver_version,memory.total,memory.used,memory.free"])
print('Active CUDA Device: GPU', torch.cuda.current_device())
print ('Available devices ', torch.cuda.device_count())
print ('Current cuda device ', torch.cuda.current_device())
output:
__Python VERSION: 3.8.3 (default, Jul 2 2020, 17:30:36) [MSC v.1916 64 bit (AMD64)]
__pyTorch VERSION: 1.7.1
__CUDA VERSION
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Thu_Jun_11_22:26:48_Pacific_Daylight_Time_2020
Cuda compilation tools, release 11.0, V11.0.194
Build cuda_11.0_bu.relgpu_drvr445TC445_37.28540450_0
__CUDNN VERSION: 8004
__Number CUDA Devices: 1
__Devices
Active CUDA Device: GPU 0
Available devices 1
Current cuda device 0
The code I’m running is:
device = torch.device('cuda')
criterion = nn.NLLLoss()
# Only train the classifier parameters, feature parameters are frozen
optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)
model.to(device)
epochs = 1
steps = 0
running_loss = 0
print_every = 1
for epoch in range(epochs):
for inputs, labels in trainloader:
start_time=time.time()
steps += 1
# Move input and label tensors to the default device
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
logps = model.forward(inputs.to(device))
loss = criterion(logps, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if steps % print_every == 0:
test_loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
logps = model.forward(inputs).to(device)
batch_loss = criterion(logps, labels)
test_loss += batch_loss.item()
# Calculate accuracy
ps = torch.exp(logps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor)).item()
print(f"Device = {device};"
f"Epoch {epoch+1}/{epochs}.. "
f"Train loss: {running_loss/print_every:.3f}.. "
f"Test loss: {test_loss/len(testloader):.3f}.. "
f"Test accuracy: {accuracy/len(testloader):.3f}")
print(time.time()-start_time)
running_loss = 0
model.train()
the stats when i run my nvidia-smi and task manger: