Hello, I created a neural network to predict the x center of my palm. It consists of 2 cnn followed by a max pooling layer and 2 linear layers. The input is 720x720 image. Here is the code of the nn:
class MyNeuralNetwork(torch.nn.Module):
def __init__(self):
super(MyNeuralNetwork, self).__init__()
self.conv1 = torch.nn.Conv2d(4, 5, 5)
self.conv2 = torch.nn.Conv2d(5, 5, 5)
self.pool = torch.nn.MaxPool2d(3, 3)
self.linear1 = torch.nn.Linear(5 * 78 * 78, 100)
self.linear2 = torch.nn.Linear(100, 1)
def forward(self, x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.linear1(x)
x = self.linear2(x)
return x
and here is my Dataloader:
class MyHand(Dataset):
"""Creating the proper dataset to feed my neural network"""
def __init__(self, name_path, root_dir, results_path, transform=None):
self.names = pd.read_csv(name_path)
self.rootdir = root_dir
self.transform = transform
self.results = pd.read_csv(results_path)
def __len__(self):
length = len(self.names.columns)
return length
def __getitem__(self, index):
img_path = os.path.join(self.rootdir, self.names.columns[index])
image = pl.imread(img_path)
x_center = torch.tensor(self.results.iloc[index, 0])
if self.transform:
image = self.transform(image)
return image, x_center
and the part of the code for training:
EPOCHS = 5
LEARNING_RATE = 0.001
model = MyNeuralNetwork()
criterion = torch.nn.MSELoss()
optimizer = optim.SGD(model.parameters(), LEARNING_RATE)
for epoch in range(EPOCHS):
print("epoch:", epoch)
for batch, (pic, x_center) in enumerate(loader):
outpout = model(pic)
loss = criterion(outpout/720, x_center/720)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(loss)
As you can see below my model predicts the same result for every batch at each epoch, thus the weights and bias are not updated
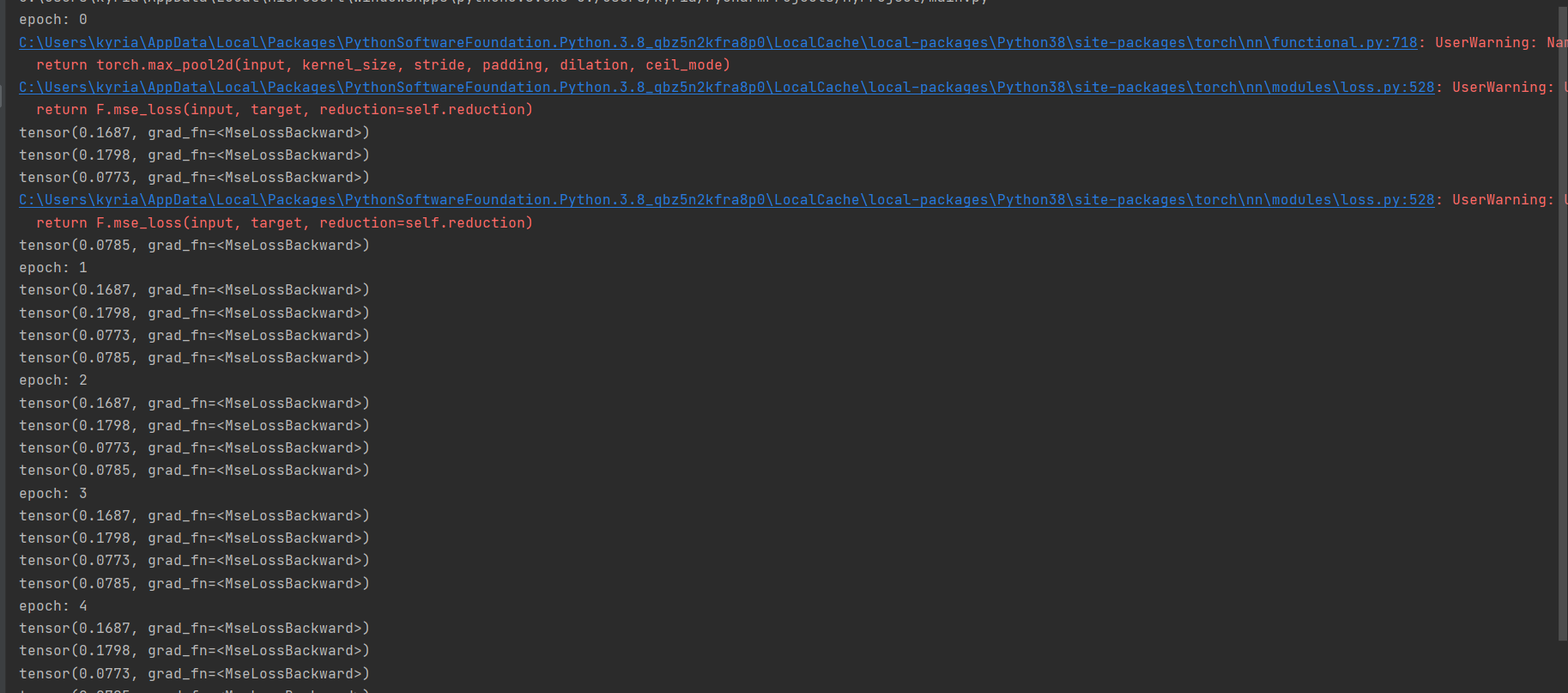
also the warning that are not showed fully in the screenshot are:
- UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at …\c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
2( the warning is twice): UserWarning: Using a target size (torch.Size([4])) that is different to the input size (torch.Size([4, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
return F.mse_loss(input, target, reduction=self.reduction)