I built my own Transformer model in pytorch based on “Attention is all you need” to perform machine translation task.
But unfortunately, this does not work well because the train loss does not decreas properly and validation loss even increases.
In addition, BLEU score which I used to evaluate model performance keeps staying 0, which I don’t find the reason.
I post this topic for advice on programming a transformer.
I don’t know which part of my code is wrong, so I think I should know overall idea of Transformer.
In my opinion, the model itself is not a problem since I referred to a blog’s tutorial on implementing Transformers.
So I think the problem is data preprocessing or training procedure.
I prepared for English/French dataset, tokenized with SentencePiece, and pre-processed data with below forms.
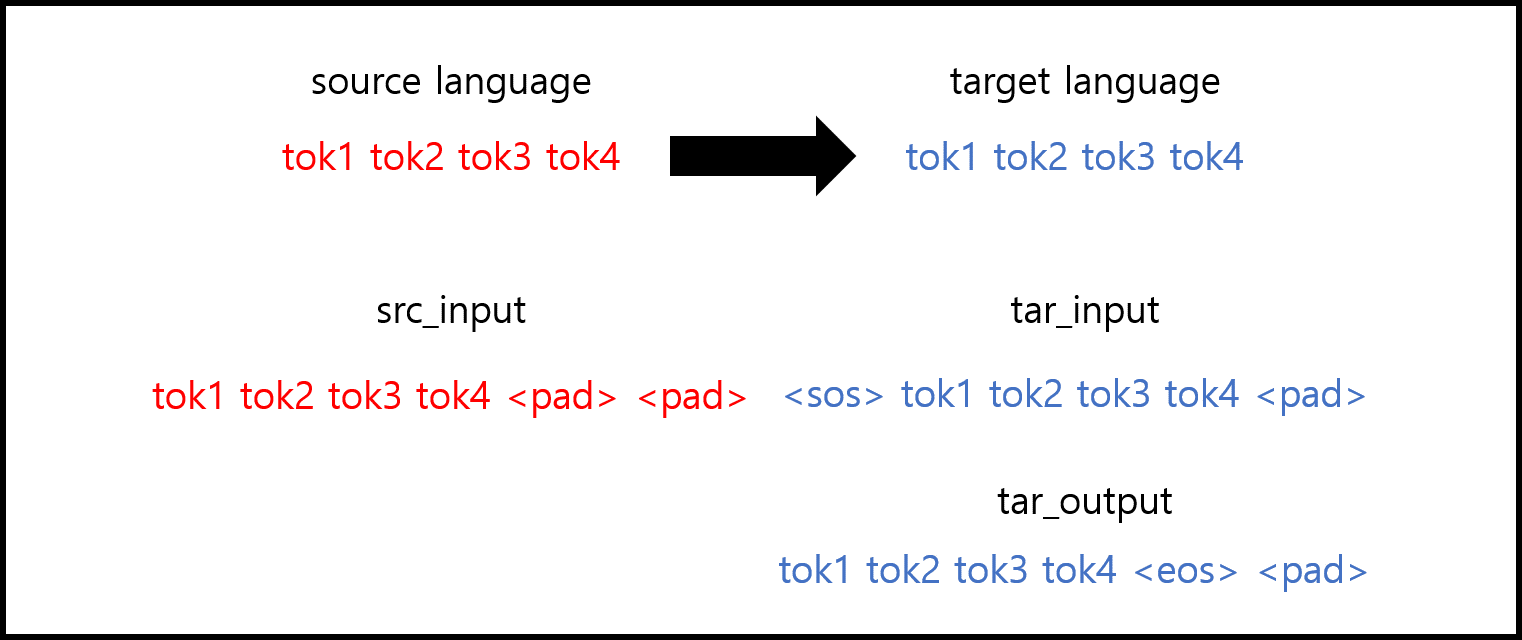
If we say the max length is 6, then we should add paddings like above.
And I want to know this is a right method.
I put src_input to encoder and tar_input to decoder as a target input.
Then after getting final output in shape (batch_size, max_len, target_vocab_size), I put this LogSoftmax layer and calculated NllLoss with tar_output.
This is codes of data pre-processing.
def add_padding(tokenized_text):
if len(tokenized_text) < seq_len:
left = seq_len - len(tokenized_text)
padding = [pad_id] * left
tokenized_text += padding
return tokenized_text
def process_src(text_list):
print("Tokenizing & Padding src data...")
tokenized_list = []
for text in tqdm(text_list):
tokenized = src_sp.EncodeAsIds(text.strip())
tokenized_list.append(add_padding(tokenized))
print(f"The shape of src data: {np.shape(tokenized_list)}")
return tokenized_list
def process_tar(text_list):
print("Tokenizing & Padding tar data...")
input_list = []
output_list = []
for text in tqdm(text_list):
tokenized = tar_sp.EncodeAsIds(text.strip())
input_tokenized = [sos_id] + tokenized
output_tokenized = tokenized + [eos_id]
input_list.append(add_padding(input_tokenized))
output_list.append(add_padding(output_tokenized))
print(f"The shape of tar(input) data: {np.shape(input_list)}")
print(f"The shape of tar(output) data: {np.shape(output_list)}")
return input_list, output_list
And this is for training.
def train(self):
print("Training starts.")
for epoch in range(1, num_epochs+1):
self.model.train()
train_losses = []
train_bleu_scores = []
best_valid_loss = sys.float_info.max
for i, batch in tqdm(enumerate(self.train_loader)):
src_input, tar_input, tar_output, encoder_mask, masked_attn_mask, attn_mask = batch
src_input, tar_input, tar_output, encoder_mask, masked_attn_mask, attn_mask = \
src_input.to(device), tar_input.to(device), tar_output.to(device),\
encoder_mask.to(device), masked_attn_mask.to(device), attn_mask.to(device)
output = self.model(src_input, tar_input, encoder_mask, masked_attn_mask, attn_mask) # (B, L, vocab_size)
self.optim.zero_grad()
loss = self.criterion(output.view(-1, sp_vocab_size), tar_output.view(batch_size * seq_len))
loss.backward()
self.optim.step()
train_losses.append(loss.item())
output_list = torch.argmax(output, dim=-1).tolist()
tar_output_list = tar_output.tolist()
decoded_output_list, decoded_tar_output_list = self.decode_tokens(output_list, tar_output_list)
train_bleu_score = metrics.bleu_score(decoded_output_list, decoded_tar_output_list, max_n=4)
train_bleu_scores.append(train_bleu_score)
mean_train_loss = np.mean(train_losses)
mean_bleu_score = np.mean(train_bleu_scores)
print(f"Epoch: {epoch}||Train loss: {mean_train_loss}||Train BLEU score: {mean_bleu_score}")
summary.add_scalar('loss/train_loss', mean_train_loss, epoch)
summary.add_scalar('bleu/train_bleu', mean_bleu_score, epoch)
valid_loss, valid_bleu_score = self.validation()
summary.add_scalar('loss/valid_loss', valid_loss, epoch)
summary.add_scalar('bleu/valid_bleu', valid_bleu_score, epoch)
if valid_loss < best_valid_loss:
if not os.path.exists(ckpt_dir):
os.mkdir(ckpt_dir)
torch.save(self.model.state_dict(), f"{ckpt_dir}/best_model.pth")
print(f"Current best model is saved.")
best_valid_loss = valid_loss
print(f"Best validation loss: {best_valid_loss}||Validation loss: {valid_loss}||Valid BLEU score: {valid_bleu_score}")
print(f"Training finished!")
Please point out if I am mistaken.
Thank you very much.