I’ve recently been learning about parallel computing in Pytorch, and I start with Dataparallel (I want to dive into the principles of parallel computing even though I know it is no longer recommended). I read some blogs and got some understanding of Dataparallel.
I would like to present some of my understanding of the Dataparallel process before raising my doubts.
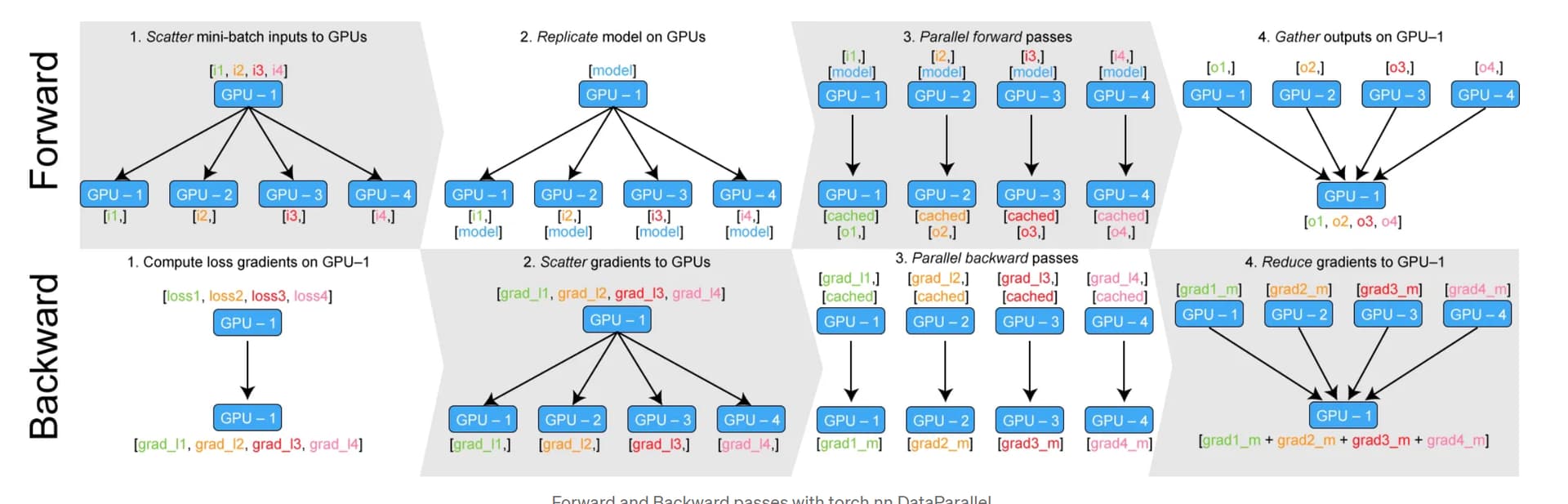
My understanding: (1) Typically, the model and data (a batch) are first placed on the main GPU (GPU0); (2) Dataparallel first slices the data to each GPU and makes a copy of the model and sends the copy to each GPU; (3) Each GPU performs computation to get the output; (4) All GPUs merge the outputs and send them to the main GPU; (5) The main GPU computes the loss from all the data; (6) The operation of splicing the outputs of each GPU into a whole output in step 4 is derivable, so the computation of the loss calculates the loss of a subset of the data from each GPU, namely, loss1,loss2, etc.; (7) each GPU computes the gradient from its respective loss; (8) each GPU updates the model by merging the gradients to the main GPU.
Since Dataparallel has some source code implemented in c++, I can’t view it directly. So I have some doubts: (1) The data and model itself is on the main GPU, so when slicing the data does the main GPU need to accept the data again? Similarly, does the copy of the model need to be passed to the main GPU once more? (2) Is my description of step 6 correct? As you can see from the figure below, there is a separate loss for each GPU, whereas in step 4 the loss is calculated for all the data, so I guess the process is step 6; (3) Why is the gradient summed up and not averaged.
Also, I have a question. If my model returns not only the output but also the loss during forward propagation. Then is calculating the final loss just a matter of averaging the returned losses?
Is it reasonable to average the losses directly, as shown below?
class My_Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(768, 76800)
self.relu = torch.nn.ReLU()
self.classfier = torch.nn.Linear(76800, 1)
self.loss_fn = torch.nn.MSELoss()
def forward(self, x, y, y2):
result = self.classfier(self.relu(self.linear1(x)))
loss1 = self.loss_fn(result.reshpae(-1), y)
loss2 = self.loss_fn(result.reshpae(-1), y2)
return result, loss1+loss2
model = My_Model()
model = model.cuda()
model = nn.parallel.DataParallel(model, device_ids=[0,1])
# x is input, y and y2 are labels
result, loss = model(x, y, y2)
# Is it OK?
loss = loss.mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()