Hi all,
I am new to NLP, now I was practicing on the Yelp Review Dataset and tried to build a simple LSTM network, the problem with the network is that my validation loss decreases to a certain point then suddenly it starts increasing. I’ve applied text preprocessing and also dropouts but still no luck with those. What should I do to prevent overfitting?
I am attaching a terminal screenshot for reference.
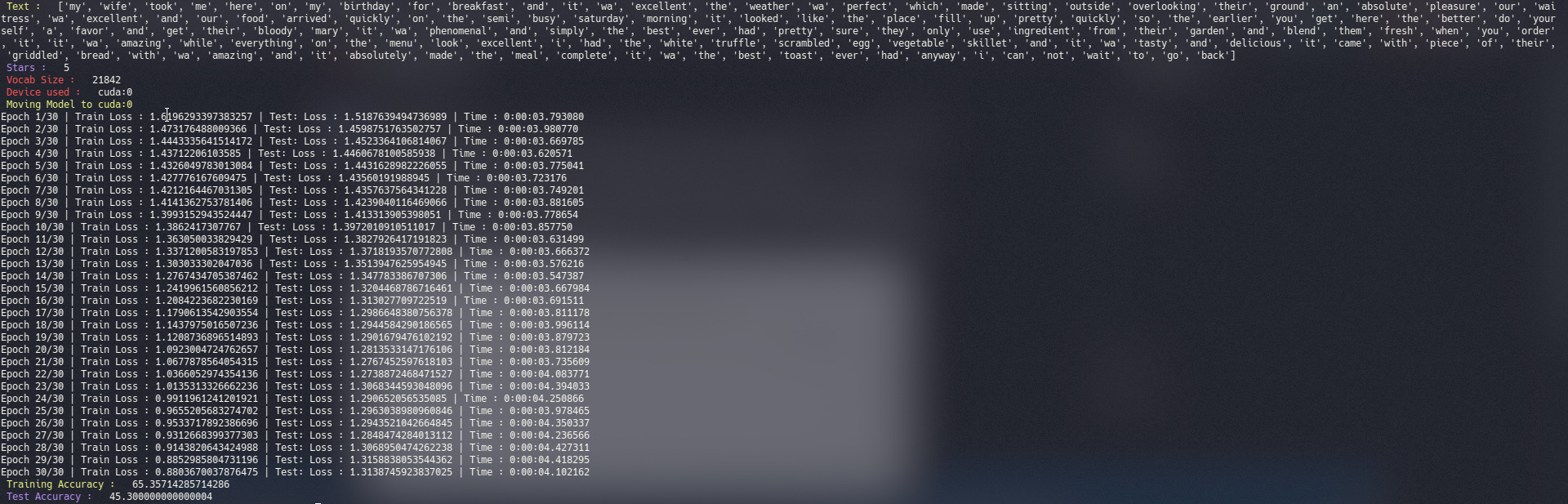
and my network architecture is as follows:
class RNN(nn.Module):
def __init__(self, n_vocab, embed_dim, n_hidden, n_rnnlayers, n_outputs):
super(RNN, self).__init__()
self.V = n_vocab
self.D = embed_dim
self.M = n_hidden
self.K = n_outputs
self.L = n_rnnlayers
self.embed = nn.Embedding(self.V, self.D)
self.rnn = nn.LSTM(
input_size=self.D,
hidden_size=self.M,
num_layers=self.L,
batch_first=True)
self.dropout = nn.Dropout(p=0.2)
self.fc = nn.Linear(self.M, self.K)
def forward(self, X):
# initial hidden states
h0 = torch.zeros(self.L, X.size(0), self.M).to(device)
c0 = torch.zeros(self.L, X.size(0), self.M).to(device)
# Embedding layer
# turns word indices to word vectors
out = self.embed(X)
# get RNN unit output
out, _ = self.rnn(out, (h0, c0))
# max pool
out, _ = torch.max(out, 1)
out = self.dropout(out)
out = self.fc(out)
return out