I am working on a GAN with a novel architecture: the GAN is trying to block a single square of fixed dimension within the image. It outputs a one-hot vector of x- and y-coordinates of the top-left corner of the square which are then turned into an image-sized filter representing the whole square by adding the one-hot vector to itself with various offsets. The (slightly messy) code for doing so is below.
# we first have to add the zero offset to the end of the one-hot-vec
# s_bs is the size of the 'blocking square'
full_zeros = Variable(torch.zeros(batch_sz, self.s_bs))
ohv_y_full = torch.cat([ohv_y, full_zeros], dim=1)
ohv_x_full = torch.cat([ohv_x, full_zeros], dim=1)
# add the correct size offset to the front and to the back
for i in range(1, self.s_bs):
trailing_zeros = Variable(torch.zeros(batch_sz, self.s_bs-i))
leading_zeros = Variable(torch.zeros(batch_sz, i))
ohv_y_full+= torch.cat([leading_zeros, ohv_y, trailing_zeros], dim=1)
ohv_x_full+= torch.cat([leading_zeros, ohv_x, trailing_zeros], dim=1)
Basically for s_bs=3 this will do:
[0.1,1,0.2,0,0,0] →
[0.1,1.1,1.3,1.2,.2,0,0,0]
(going from a vector of size s to size s + s_bs - 1)
I am using cross entropy loss. I reverse the loss in order to do gradient ascent:
for group in optimizer.param_groups:
for p in group['params']:
p.grad = -1*p.grad
However, as soon as I do this, my loss becomes nan, unless I use a learning rate of about 1e-10, which is obviously too low, and the model never converges. If I comment out the reversal of the loss, then it works just fine. Additionally, if I reverse the loss but use s_bs=1, it also works just fine. Besides the step for turning the one-hot-vector into a square, the setup I have for my GAN is pretty straight-forward. Does anyone have any insight as to why my setup is causing me to have an unstable loss? Or does anyone have any alternative suggestions for how to do that step? Ideally I would do something like np.convolve but there is not a pytorch version of that with autograd.
Edit: Here is the computation graph for ohv_y_full:
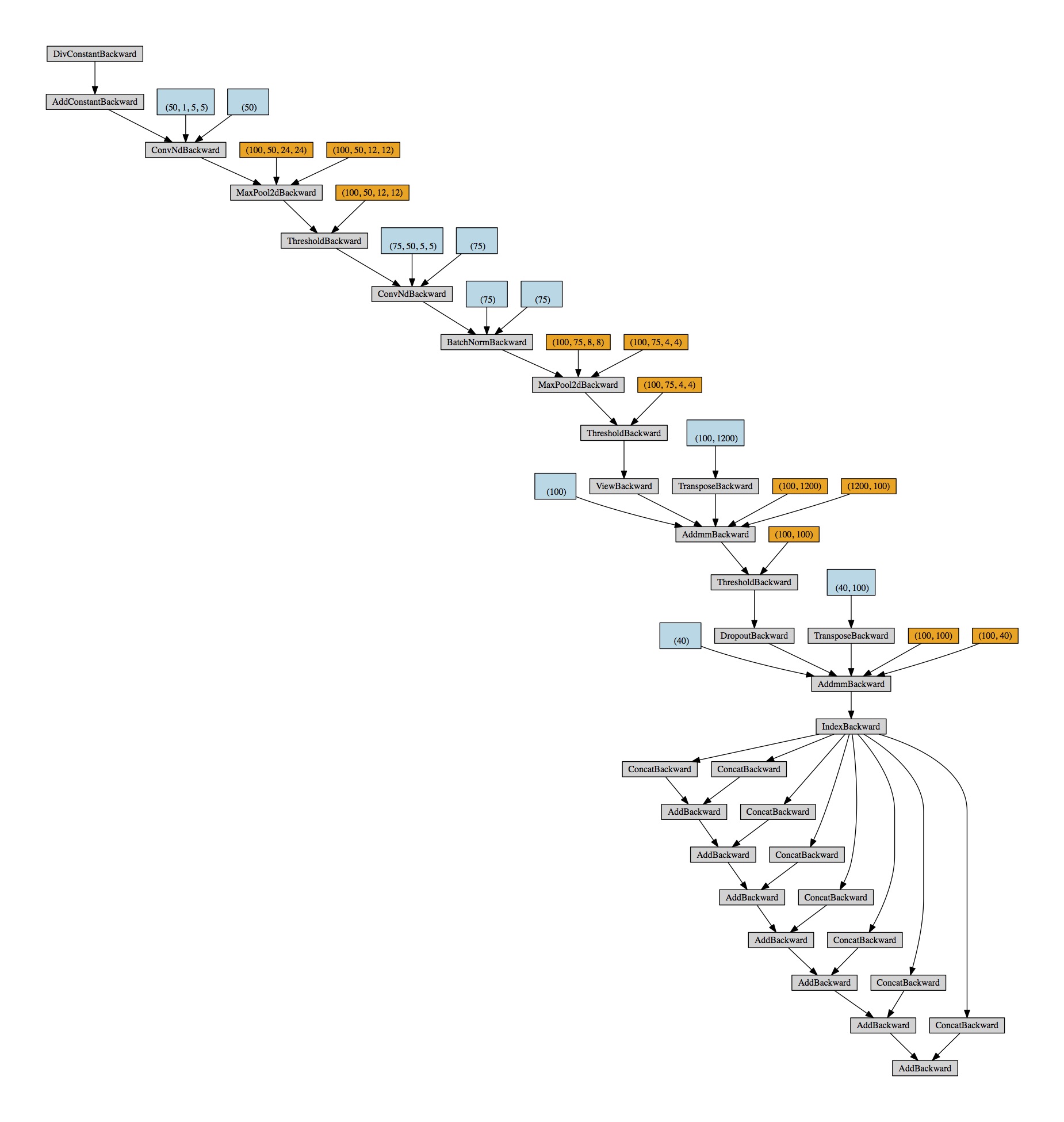
Thanks!!