I am training a speech to text model, following is my training loop:
for i in range(epochs):
print(f"Epoch {i+1}/{epochs}")
wer = 0
mer = 0
wil = 0
running_loss = 0
for data in tqdm(train_dataloader):
# Every data instance is an input + label pair
inputs, labels, input_lengths, label_lengths = data
inputs, labels = inputs.to(device, dtype=torch.float32), labels.to(device, dtype=torch.float32)
print(torch.max(inputs), torch.min(inputs))
# Zero your gradients for every batch!
optimizer.zero_grad()
# Make predictions for this batch
inputs = inputs.permute(0,2,1) # (1, 1729, 400)
outputs = model(inputs)
print(outputs.shape) # 1, 1729, 29 [N, num_frames, probs]
print(outputs)
# Compute the loss and its gradients
loss = criterion(outputs, labels, input_lengths, label_lengths)
loss.backward()
# Error metrics
decoded_preds, decoded_targets = GreedyDecoder(outputs.transpose(0, 1), labels, label_lengths) # to debug model's output and ground truth
measures = jiwer.compute_measures(decoded_preds, decoded_targets)
wer += measures['wer']/inputs.shape[0]
mer += measures['mer']/inputs.shape[0]
wil += measures['wil']/inputs.shape[0]
running_loss += loss.item()/inputs.shape[0]
print(decoded_preds)
print(decoded_targets)
# Adjust learning weights
optimizer.step()
print("WER :", wer)
print("MER :", mer)
print("WIL :", wil)
print("Loss :", running_loss)
break
just to test I am using a batch_size=1 in my dataloader and optimizer which I am using is AdamW with lr=1e-4 and criterion as CTCLoss()
but after first step, output of model becomes nan for some reason and I suspect that its happening because of the optimizer.step()
Following is the output after first step:
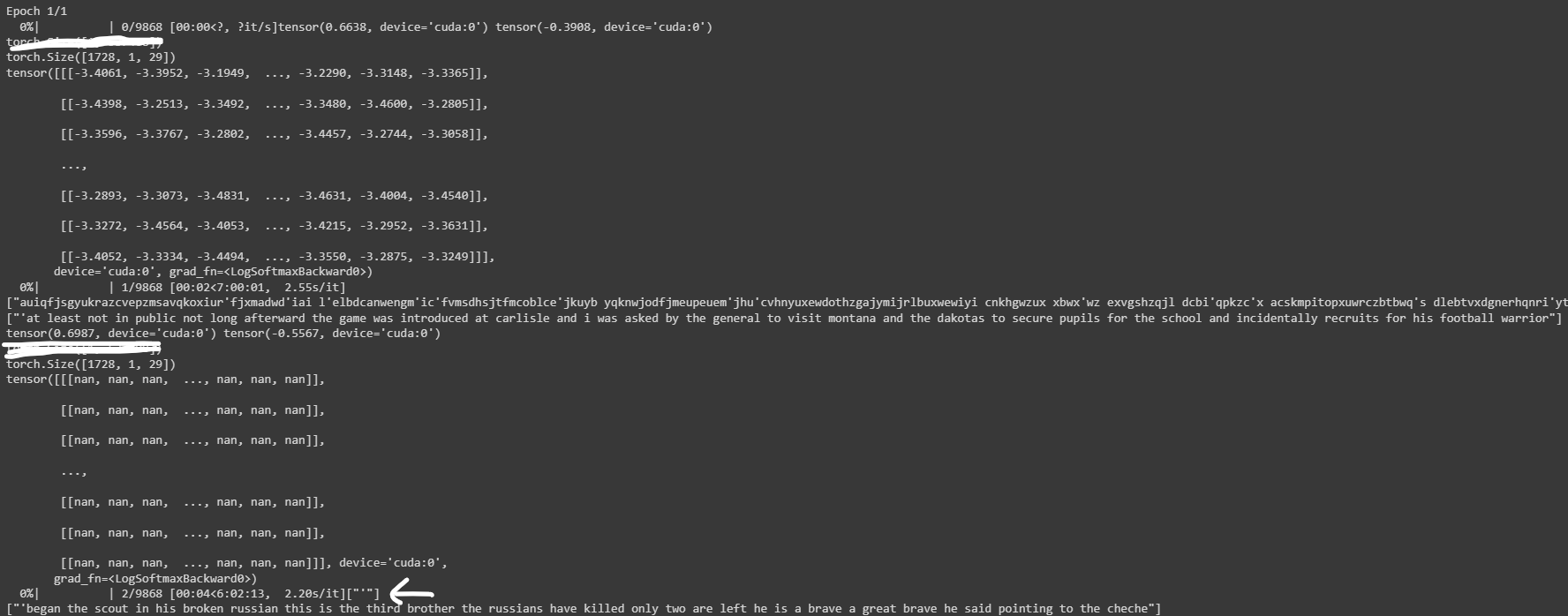
Why is this happening? and how can I resolve this issue?
Thank you ![]()