Question
I want to analysis the speed of distributed data parallel training of alexnet. But I find that the speed of allreduce invoked during alexnet training is slower than that directly invoked by nccl-tests or pytorch allreduce test.
Environment
- pytorch1.5 + cuda9.0 + nccl2.7.8
- 4x1080ti
Details of Performance
Alexnet has about 244MB parameters, so I test the allreduce performance of this communication volume with 4 devices.
Speed of nccl allreduce by directly testing
I use nccl-tests to test allreduce. The time cost is about 50.5ms.
I also test it with the following pytorch code. The time cost is about 50.4ms.
def all_reduce_latency(nbytes):
buf = torch.randn(nbytes // 4).cuda()
torch.cuda.synchronize()
# warmup
for _ in range(5):
dist.all_reduce(buf)
torch.cuda.synchronize()
torch.cuda.synchronize()
begin = time.perf_counter()
for _ in range(25):
dist.all_reduce(buf)
torch.cuda.synchronize()
end = time.perf_counter()
avg_speed = (end - begin) * 1e6 / 25
return avg_speed
Speed of nccl allreduce in alexnet training
I use ddp with a very large bucket size to force that all gradient are fused to a single buffer, and the gradient communication is not overlapped with computation. I found that the speed of allreduce is about 67.2ms, which is very slow.
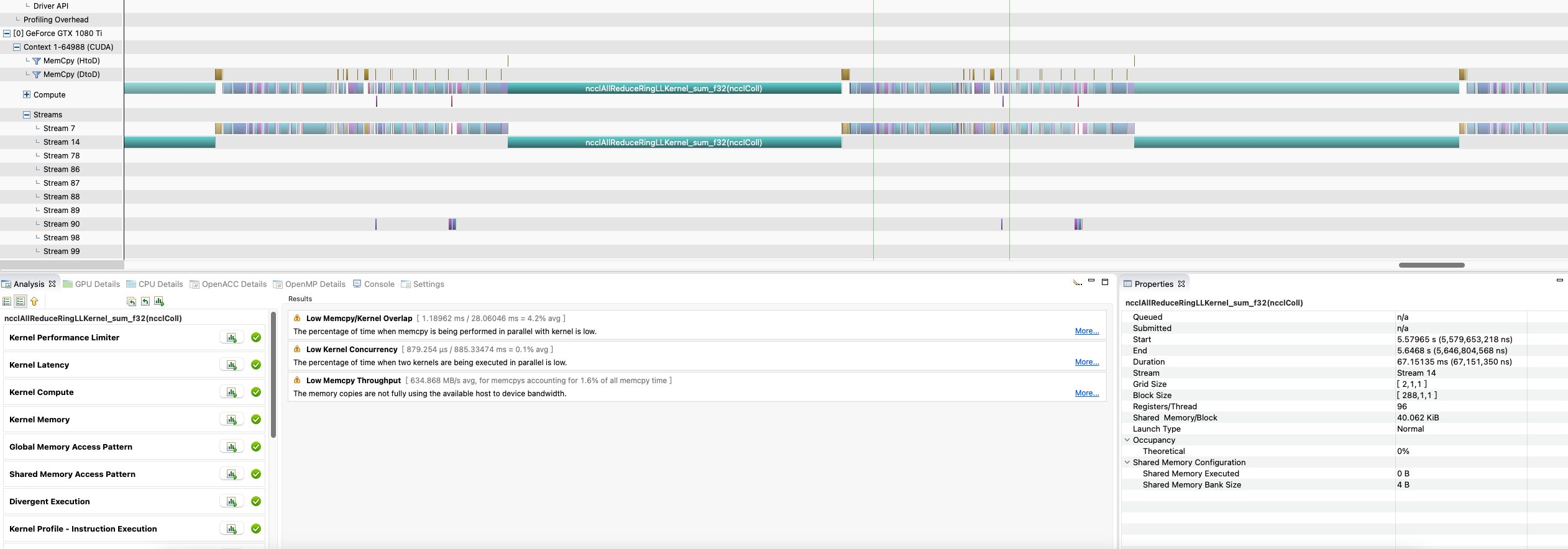
I also tried manually fuse gradients to a buffer to call allreduce instead of using ddp. There is no difference. NCCL allreduce is much slower when called during alexnet training. I don’t know what cause this. Can you give some suggestions to find this problem?
Thanks a lot!